Performing ETL using Kettle with GPFDIST and GPLOAD

Scenario:
We have a remote datasource, served by a gpfdist server. We need to import the data in a Greenplum database, while performing some ETL manipulation during the import.
It is possible to accomplish this goal with a simple transformation in a few steps using Kettle.
For the sake of simplicity, I assume that:
- You know Kettle basics, like connections, jobs, and translations – for further information you can look at my previous article on Kettle and Greenplum
- You have a very simple test database on Greenplum, with one table. For the purposes of this article I used a small table called “test” with two columns “id” and “md5“.
- A GPFDIST server running, with a csv file exposed.
- GPLOAD installed on your machine. You can download it for your architecture from the Greenplum Site : http://www.greenplum.com/community/downloads/
Using external tables
With Greenplum’s external tables and parallel file server, gpfdist, efficient data loads can be achieved.
Using the “SqlScript” component, we can create an external table at the beginning of our transformation.
The “Create External Table“, as shown below creates an external table, named “external_samples”. Data is provided by one location in our case, but two or more locations on the same ETL server can be used. One instance of gpfdist is running on this server, on port 8081. Double click on the “SQLScript” component and insert the code for the creation of an external table – for example this is our script:
drop external table if exists "public".external_samples;
create external table "public".external_samples(
id int ,
md5 text
)
location('gpfdist://bravo01:8081/testdata.txt')
format 'TEXT' (DELIMITER ',')this is a simple test table, with 2 columns:
- id
- md5
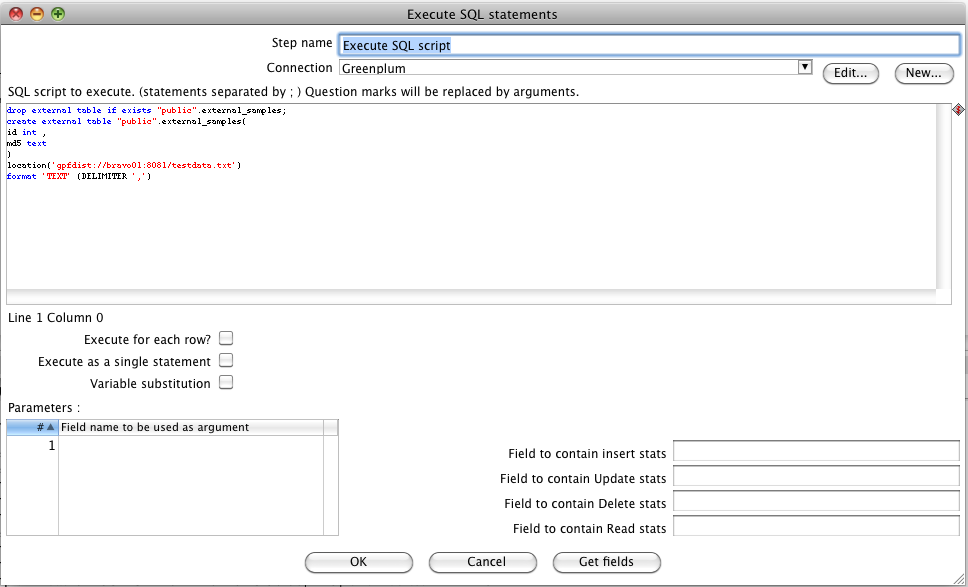
Using the “DELIMITER” keyword at the end of the sql script, Greenplum will use the ‘,’ character as delimiter of the columns, like a CSV file.
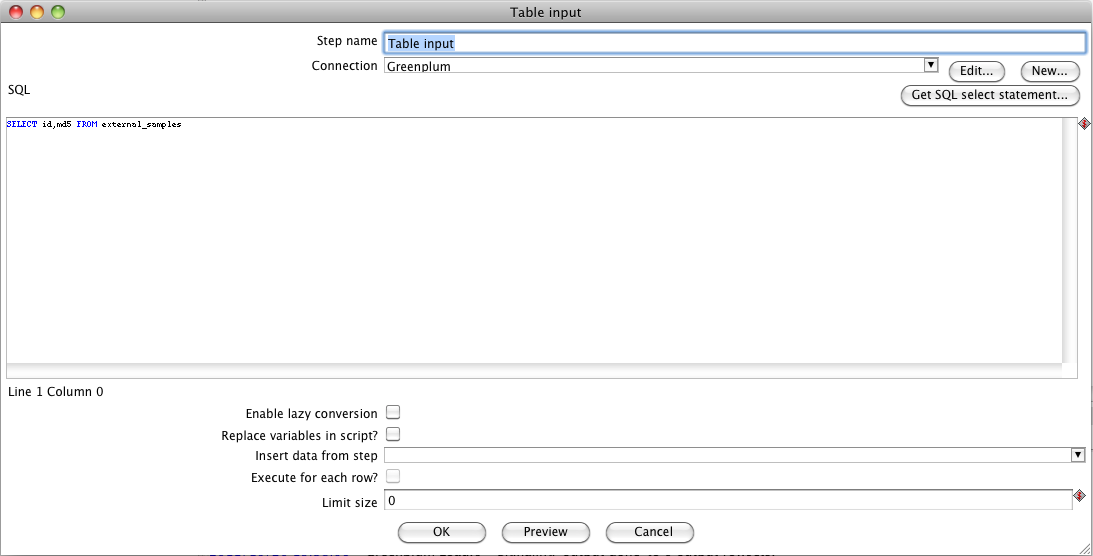
Now we have a read only table. Drag a “Table input” component and drop it in the design panel. Connect the script component to the input table component, and double click on the table one.
Insert the select statement by specifying the columns you wish to import. For example:
SELECT id,md5 FROM external_samples;This will perform the extraction of the data from the external table.
This Stream of data can be used for some manipulations. For the sake of simplicity no ETL operations will be performed in this article (for an introduction on ETL with Greenplum and Kettle, you can read my previous article : “ETL with Kettle and Greenplum“), so we can focus on the use of the GPFDIST and GPLOAD components.
Using the Greenplum Load component
From the bulk loading folder, inside the Design tab on the left side of the Kettle window, drag a “Greenplum Load” component, and drop it near the “Table Input” element. Then connect the two elements.
Now double click on the “Greenplum Loader” component.
Choose, as usal, the connection that has to be used.
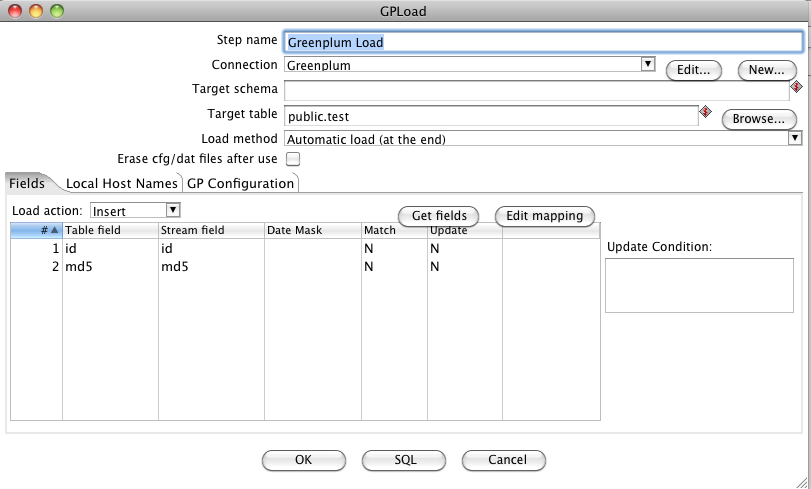
IMPORTANT
Due to a Bug, if you fill the “target schema” field, the component will generate a configuration file with wrong format, so leave the schema field alone, and fill the “Target Table” with the <schema>.<table> syntax.
We are almost there.
We need to map the table fields and the stream fields. However, the external table that we want to create, at the moment doesn’t exist yet on the server. So, we have to map them manually.
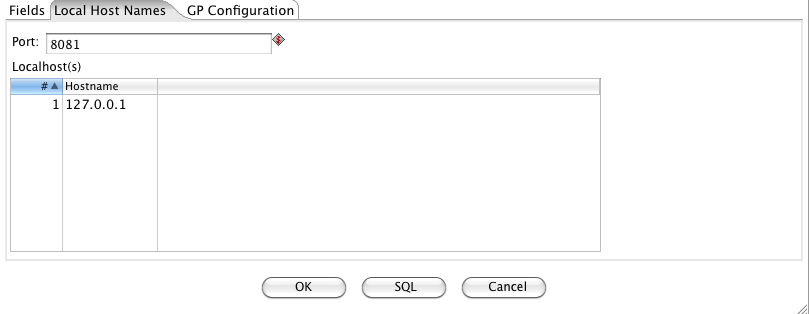
On the “localhost names” panel you have to specify which port number gpfdist file distribution program uses – typically 8081 works fine. Be sure to choose a free port. Also you have to insert the IP of the machine running gpload (usually it is localhost or 127.0.0.1). If the host is using several NIC cards then the host name or IP address of each NIC card can be specified.
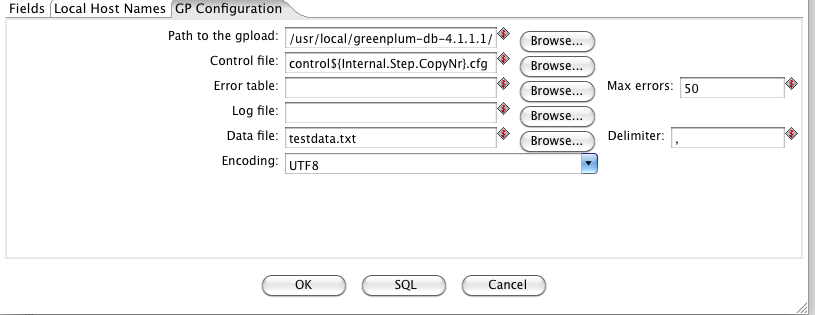
In the “GP Configuration” tab you can insert the path to where the GPload utility is installed. It is possible to define the name of the GPload control file that will be generated and the name of the Data file(s) that will be written for subsequent load operations in the target tables by GPload (you can also specify the encoding and the file column delimiter).
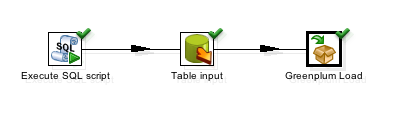
Once all the elements are configured and connected, your transformation should look like this:
Execute the transformation. Everything should work fine, and the data will be imported in the destination table.