
Back to the PG
I’m very excited to become a 2ndQuadrant member. I was involved in PostgreSQL activities in NTT group (Japanese leading ICT company, see here and here), including log shipping replication and PostgreSQL scale out solution as PostgresXC and PostgresXL.
At NTT I had several chances to work very closely with 2ndQuadrant. After three years involvement in deep learning and accelerator usage in various applications I’m now back to PostgreSQL world. And I’m still very interested in PostgreSQL scale out solutions and applying PostgreSQL to large scale analytic workload as well as stream analytics.
Here, I’d like to begin with a discussion of scaled out parallel distributed database with full transaction capabilities including atomic visibility.
ACID property, distributed database and atomic visibility
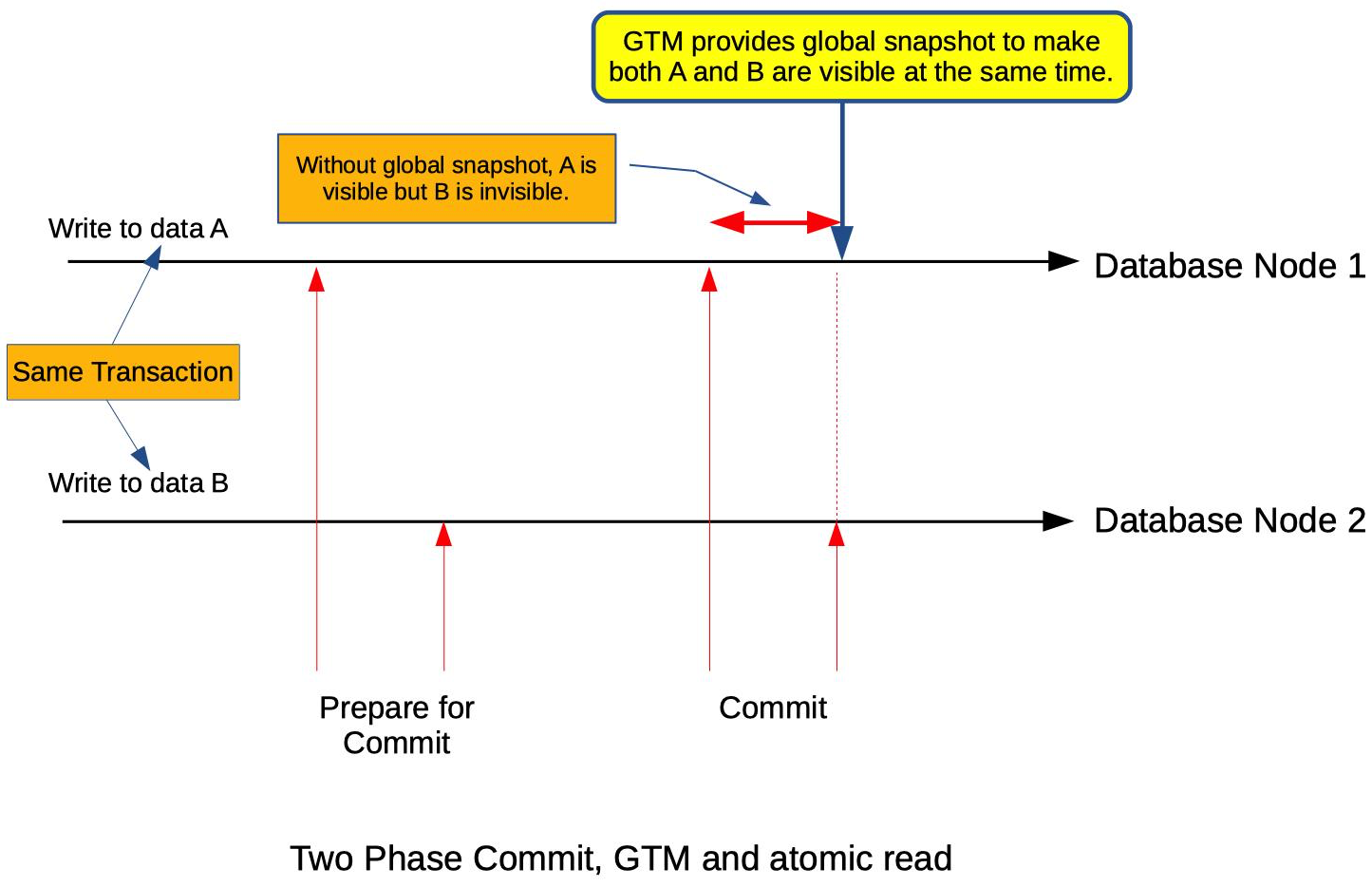
Traditionally, providing full ACID property is the responsibility of each database server. In scale out solutions, database consists of multiple servers and two phase commit protocol (2PC) is used to provide ACID properties in updating multiple servers.
Although 2PC provides write consistency among multiple servers, we should note that it does not provide atomic visibility which ensures global transaction update can be visible to all the other transaction in a same time. In two phase commit protocol, each server receives “COMMIT” in different time clock and this can make partial transaction update visible to others.
How Postgres-XL works, global transaction management
Postgres-XL provides atomic visibility of global transaction and this is essentially what GTM (global transaction manager) is doing. GTM helps to share the snapshot among all the transactions so that any such partial COMMIT is not visible until all the COMMITs are successful and GTM updates the snapshot. Note that GTM-proxy is used to reduce interaction between each server and GTM by copying the same snapshot to different local transactions.
This is very similar to what standalone PostgreSQL is doing as MVCC. It is somewhat centralized and limits XL to run in geographically distributed environment. For example, suppose we have distributed database with servers in Europe and the US and have GTM in London. In such environment, servers in the US cannot neglect the latency between servers and GTM. Even in local environment, the number of transaction per second is limited by the maximum number of interactions per second through network.
Towards full distribution
My ongoing interest is whether we can make global atomic read really distributed, in other words, without any centralized facility? It is very important to configure geo-distributed parallel databases and improve their performance limit. I’d like to continue this topics on the series of blog for discussion.