Defining Extreme High Availability in a Postgres World


In a past examination of the topic, we strove to define high availability in context with Postgres. The advent of EDB Postgres Distributed (PGD) has changed the picture somewhat, enough that it requires new terminology. Rather than invent an entire nomenclature, we elected simply to emphasize the inherent guarantees of HA as extreme when certain qualities are present. So what is “extreme” HA? What does it have to do with PGD?
Perhaps a better framing of the question is: How does PGD build on the architectural foundation of its predecessors? We derived a functional definition of high availability in regard to Postgres in our previous examination of this topic, so let’s do the same for extreme HA and see what happens.
Where we left off
We had previously defined high availability related to Postgres as the following:
For the purpose of continuously providing database access, a quorum-backed cluster must present a writable Postgres interface independent of cluster composition. Should the current target become unusable, the cluster must identify and substitute the highest ranked online replica with the most recent Logical Sequence Number (LSN). If synchronous replication is in use, the promoted node must have at least one synchronous write target.
And that definition came with a corresponding simplified diagram:
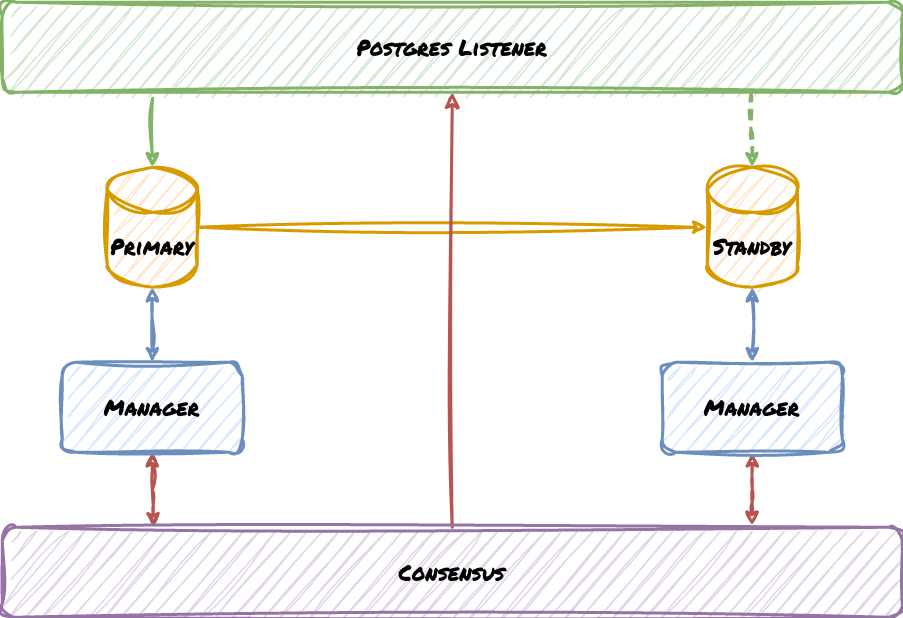
In this diagram, Green corresponds to client traffic, Yellow represents Postgres replication, Blue stands for the HA management service communicating with its assigned node, and Red pertains to communicating with the consensus layer. We’ve deliberately left the listener and consensus layer as abstract concepts because they don’t derive directly from Postgres. In actuality, everything in the diagram except for Postgres is some kind of external tooling, suggesting that even this simplified view obfuscates a much more intimidating implementation.
We can start with this and modify the definition to encompass extreme high availability.
Plugging the RTO hole
First things first: our definition does not account for deployment complexities which could affect Recovery Time Objective (RTO) requirements. This is an inadvertent omission because we often take the act of failover for granted, as most HA stacks are good enough to deliver four 9s without much effort. Four 9s of uptime allows for about 4.3 minutes of downtime per month—it’s a tight squeeze, but modern software is more than capable of delivering.
This is the portion of our definition that requires revision:
Should the current [Postgres] target become unusable, the cluster must identify and substitute the highest ranked online replica with the most recent LSN.
Luckily, rewording to incorporate RTO and Multi-Master is actually fairly simple:
Should the current [Postgres] write target become unusable, the cluster must identify and substitute another with a compatible LSN with a minimum RTO of 99.999%.
Woah! Hold on a minute! Five 9s!? That’s only about 26 seconds of downtime per month. Indeed it is, and it’s easily attainable by Multi-Master clusters like PGD for several reasons.
Let’s elaborate.
Simplified node promotion
We actually covered a bit about how PGD Proxy drastically simplifies Postgres HA cluster design relatively recently. That article included this diagram to represent a bare-minimum PGD deployment:
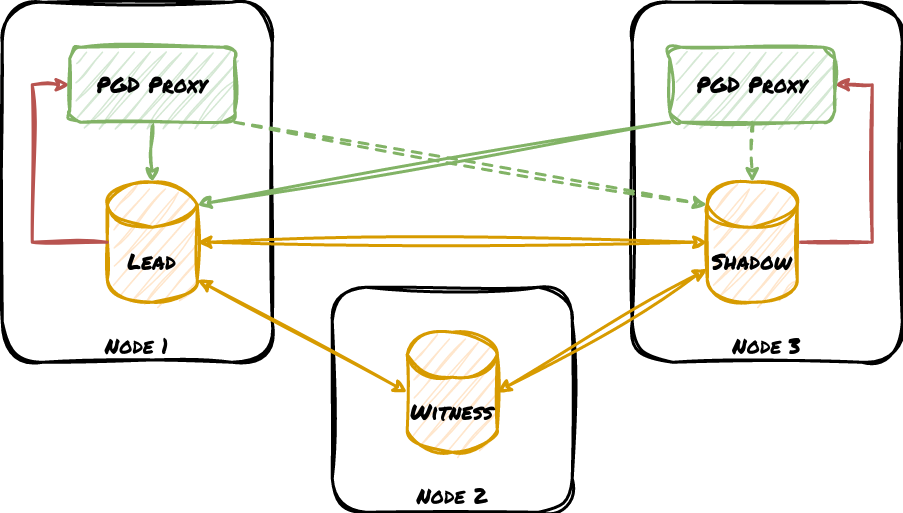
Pay attention to what’s missing in this diagram: node managers and the consensus layer. We can use this architecture because a lot happens during a standard Postgres node promotion which does not apply to PGD.
- There’s no need to promote standby nodes. That means Postgres doesn’t have to switch to a new timeline or issue a checkpoint. Clients don’t have to wait for the promotion process to complete to resume traffic.
- Connection routing is integrated through PGD Proxy. A significant portion of the promotion process includes modifying the routing layer to target the newly promoted Postgres node. Whether this is a cloud API, reconfiguring PgBouncer or a similar tool, moving a VIP, etc.
- Node status polling is not necessary. PGD Proxy receives notifications any time the cluster state changes, so it doesn’t have to poll on an interval for updates, nor repeat the checks for verification purposes.
This last point is significant. HAProxy is one of the most advanced Postgres HA systems because it directly passes cluster state to a REST interface for safer routing. But the REST interface itself must be polled. No polling interval, no matter how aggressive, can compete with a notification.
Integrated node safeguards
Split Brain is one of those pernicious issues that greatly complicates HA management. If a Primary node is part of a larger cluster, it must self-isolate if it recognizes it is no longer part of the cluster majority. This can happen during Network Partition events which split the cluster along arbitrary lines and automated failover systems must recognize this.
This kind of node fencing must also be permanent, as another node will have inevitably been promoted and received writes in the interim. In Postgres parlance, this means the old Primary must be rewound or rebuilt from the new Primary after any failover. This is inherent in Patroni due to the routing system, EFM creates files which prevent an old Primary from resuming, and repmgr has a script hook for an arbitrary fencing script.
Since PGD replication is bidirectional with conflict management, an accidental failover won’t result in lost data from Primary node ambiguity. This renders several node and network integrity verification steps as unnecessary, including Primary fencing enforcement. Despite that, PGD Proxy acts as an implicit write fence for clusters which require slightly stronger safeguards. The node itself remains online and available and does not need to be rewound, rebuilt, or otherwise modified to continue operating.
Failover in aggregate
Cumulatively, these elements within standard physical streaming replication contribute to drastically longer switchover and failover timelines. Postgres high availability stacks must periodically check node status. If the Primary vanishes, they need to verify it’s actually gone multiple times to prevent unexpected failovers, because this is an expensive event. The Primary must shut down and fence itself to prevent Split Brain. The standby must be promoted. Connection routing systems must be reconfigured. It’s a highly orchestrated dance where a single misstep could spell failure.
With PGD? PGD Proxy gets a signal that the primary write target has changed, and it sends traffic there instead. This is what gives us the freedom to incorporate RTO directly into the definition of extreme HA.
Definition distilled
Let’s examine that revised sentence from our definition again, along with the preamble:
For the purpose of continuously providing database access, a quorum-backed cluster must present a writable Postgres interface independent of cluster composition. Should the current [Postgres] write target become unusable, the cluster must identify and substitute another with a compatible LSN with a minimum RTO of 99.999%.
The implications of this phrasing is that switchover and failover are inherently reactive events. The Lead node disappears for some reason and the cluster scrambles to provide a replacement. But that’s not strictly true without a promotion process. The preamble already says we have a quorum and present a writable interface, so does it matter how we derive one?
Let’s rephrase the last sentence for what’s actually happening in a PGD cluster:
Such an interface should maintain a minimum RTO of 99.999% with no transaction discontinuity exceeding the maximum RPO.
This wording accomplishes a couple things. First, we don’t care how our writable Postgres connection arrives, just that it does so within our expected RTO. Secondly, expected behavior is tied to replayed transactions within the pool of node candidates. Now our Recovery Point Objective (RPO) can explicitly say something like, “No more than 100 transactions should be missing from a node before it is made a write target.”
This is primarily necessary on clusters that may not be explicitly compatible with PGD and still rely on a primary write target in order to avoid undesirable conflict race conditions. There are many strategies for overcoming this kind of limitation, but keeping RPO in our definition clarifies the expectations of an extremely HA cluster.
Considering groups
There are still two bits of the definition we need to address. Let’s begin with the final sentence:
If synchronous replication is in use, the promoted node must have at least one synchronous write target.
The intent is to ensure a failover target doesn’t prevent further writes once it takes over, but that’s now covered by our RTO requirement. A synchronous node is not writable if there are no other nodes to acknowledge transactions. That means we can remove this stipulation.
But conceptually we have a similar issue with the final part of the first sentence where we say this:
... independent of cluster composition.
In a PGD context, we must ensure that each PGD Router can operate regardless of the underlying node layout. Without this, the architecture of how we distribute nodes could adversely affect client connectivity.
Consider this design:
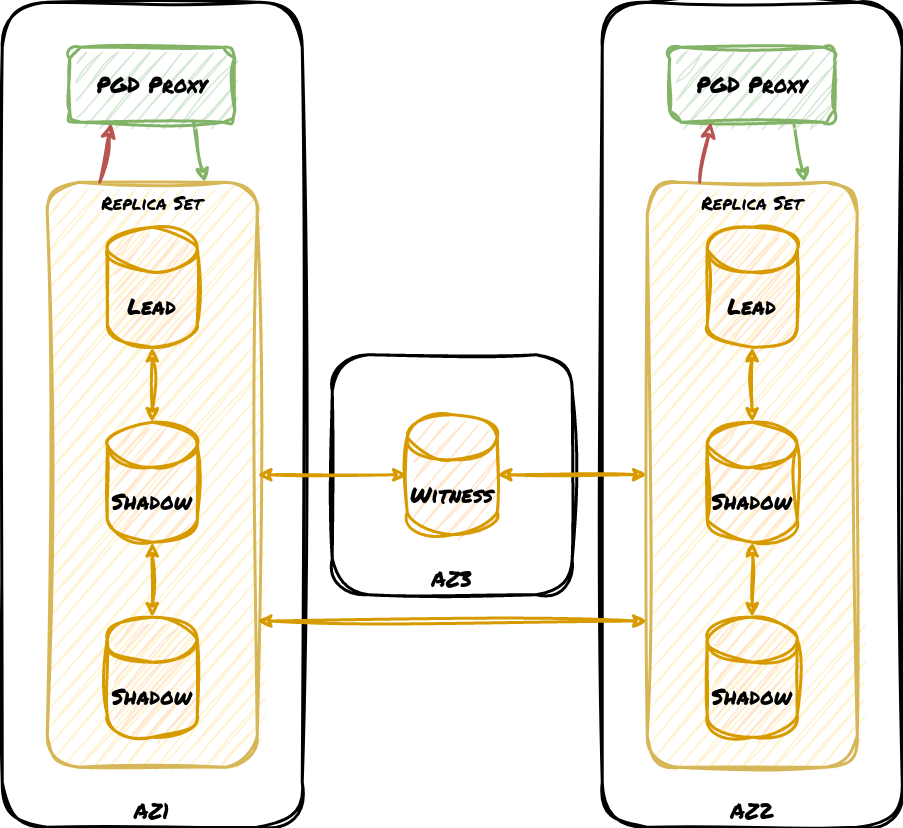
This cluster design has one write group per availability zone, and we’ve represented the cluster mesh communication simply as connections between the zones. Also keep in mind that these zones are not restricted to any single region, so this could be a worldwide deployment. This is a great cluster to use with synchronous replication since there’s always an “extra” node to acknowledge local transactions. But what if there’s a network failure that separates AZ1 from AZ2 and AZ3, yet AZ2 and AZ3 can still communicate with each other?
The introduction of PGD 5.0 makes it possible to create sub-groups that may operate semi-independently from the cluster as a whole. Each replica set may continue to accept writes for their independent group, but later integrate into the rest of the cluster once connectivity is restored. A future version of PGD Proxy takes this even further and will redirect traffic meant for AZ1 to AZ2 if all nodes in AZ1 are somehow inoperable.
This is one reason we’ve waited until now to define extreme HA; consensus sub-groups are the final cog in that particular machinery.
Including maintenance
There’s one more thing that’s incredibly important here: maintenance. It’s not something we need to include directly in the definition so long as the activity doesn’t disrupt client connections, but we would be remiss not to mention it here.
All Postgres clusters without exception will eventually need a major version upgrade. PGD provides several methods to accomplish this, and most of them can be done without simultaneously taking all nodes in the cluster offline. The best options are to use bdr_pg_upgrade on each individual node, or to add a new node while removing an old one until all nodes are replaced with the upgraded software.
Similarly, if a table becomes highly bloated and requires VACUUM FULL, the necessary table lock would normally make it unusable for the entire duration of the operation. However, since PGD uses logical replication, it’s possible to invoke VACUUM FULL on a Shadow node until all bloated tables are at their optimal size. The next step would be to switch that node to become the new Lead of the cluster or node group, and then perform the same cleanup on the previous Leader.
These are both things that are simply impossible using standard Postgres streaming replication, or any high availability technology that relies on it. The implication here is that extreme high availability requires logical replication in some capacity. So let’s tweak our language a bit by adding this to the last sentence:
… regardless of any maintenance or outage event.
This clarifies that manipulating cluster members, even in the case of a full node, site, zone, etc., outage should not affect delivery of connection continuity.
Extreme high availability defined
Given all of that, this should be our final definition:
For the purpose of continuously providing Postgres database access, a quorum-backed deployment must present a writable interface independent of cluster composition. Such an interface should maintain a minimum RTO of 99.999% with no transaction discontinuity exceeding the maximum RPO, regardless of any maintenance or outage event.
This integrates multiple concepts:
- Clients get a writable connection with five 9s of reliability.
- If a disconnection does occur, the new write target will fall within a defined RPO, including an RPO of zero to represent synchronous replication.
- Consensus is always based on quorum, even within sub-groups.
- Cluster viability is guaranteed regardless of deployment along node, zone, region, etc. considerations. More is generally “better”, but an outage of one component should not affect others.
- Outages of any kind, including maintenance such as major version upgrades that would normally require a full cluster outage, should not invalidate this guarantee.
It’s interesting that this is a simpler definition than the original, and yet it accomplishes more. Rather than being prescriptive, it’s descriptive of what the client experience should be. The only exception here is the fact we explicitly mention quorum because it serves as the basis for all of the other attributes.
We could also rephrase this to be less technical and a bit more approachable by a layman:
A Postgres cluster has extreme high availability if connections have five 9s of reliability even in the face of node, site, or region outages.
As we’ve explored in this article, that one sentence implies much more is actually happening under the hood. Achieving that level of uptime with Postgres requires extensive architectural, procedural and technical considerations that are currently only possible with EDB Postgres Distributed.