Oracle to PostgreSQL: START WITH/CONNECT BY

And now we arrive at the second article in our migration from Oracle to PostgreSQL series. This time we’ll be taking a look at the START WITH/CONNECT BY construct.
In Oracle, START WITH/CONNECT BY is used to create a singly linked list structure starting at a given sentinel row. The linked list may take the form of a tree, and has no balancing requirement.
To illustrate, let’s start with a query, and presume that the table has 5 rows in it.
SELECT * FROM person;
last_name | first_name | id | parent_id
------------+------------+----+-----------
Dunstan | Andrew | 1 | (null)
Roybal | Kirk | 2 | 1
Riggs | Simon | 3 | 1
Eisentraut | Peter | 4 | 1
Thomas | Shaun | 5 | 3
(5 rows)Here is the hierarchic query of the table using Oracle syntax.
select id, parent_id
from person
start with parent_id IS NULL
connect by prior id = parent_id;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3And here it is again using PostgreSQL.
WITH RECURSIVE a AS (
SELECT id, parent_id
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT id, parent_id FROM a;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3
(5 rows)This query makes use of a lot of PostgreSQL features, so let’s go through it slowly.
WITH RECURSIVEThis is a “Common Table Expression” (CTE). It defines a set of queries that will be executed in the same statement, not just in the same transaction. You may have any number of parenthetical expressions, and a final statement. For this usage, we only need one. By declaring that statement to be RECURSIVE, it will iteratively execute until no more rows are returned.
SELECT
UNION ALL
SELECTThis is a prescribed phrase for a recursive query. It is defined in the documentation as the method for distinguishing the starting point and recursion algorithm. In Oracle terms, you can think of them as the START WITH clause unioned to the CONNECT BY clause.
JOIN a ON a.id = d.parent_idThis is a self-join to the CTE statement that provides the previous row data to the subsequent iteration.
To illustrate how this works, let’s add an iteration indicator to the query.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT * FROM a;
id | parent_id | recursion_level
----+-----------+-----------------
1 | (null) | 1
4 | 1 | 2
3 | 1 | 2
2 | 1 | 2
5 | 3 | 3
(5 rows)We initialize the recursion level indicator with a value. Note that in the rows that are returned, the first recursion level only occurs once. That’s because the first clause is only executed once.
The second clause is where the iterative magic happens. Here, we have visibility of the previous row data, along with the current row data. That allows us to perform the recursive calculations.
Simon Riggs has a very nice video about how to use this feature for graph database design. It’s highly informative, and you should take a look.

You might have noticed that this query could lead to a circular condition. That is correct. It is up to the developer to add a limiting clause to the second query to prevent this endless recursion. For example, only recursing 4 levels deep before just giving up.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level --<-- initialize it here
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1 --<-- iteration increment
FROM person d
JOIN a ON a.id = d.parent_id
WHERE d.recursion_level <= 4 --<-- bail out here
) SELECT * FROM a;The column names and data types are determined by the first clause. Notice that the example uses a casting operator for the recursion level. In a very deep graph, this data type could also be defined as 1::bigint recursion_level.
This graph is very easy to visualize with a small shell script and the graphviz utility.
#!/bin/bash -
#===============================================================================
#
# FILE: pggraph
#
# USAGE: ./pggraph
#
# DESCRIPTION:
#
# OPTIONS: ---
# REQUIREMENTS: ---
# BUGS: ---
# NOTES: ---
# AUTHOR: Kirk Roybal (), kirk.roybal@2ndquadrant.com
# ORGANIZATION:
# CREATED: 04/21/2020 14:09
# REVISION: ---
#===============================================================================
set -o nounset # Treat unset variables as an error
dbhost=localhost
dbport=5432
dbuser=$USER
dbname=$USER
ScriptVersion="1.0"
output=$(basename $0).dot
#=== FUNCTION ================================================================
# NAME: usage
# DESCRIPTION: Display usage information.
#===============================================================================
function usage ()
{
cat <<- EOT
Usage : ${0##/*/} [options] [--]
Options:
-h|host name Database Host Name default:localhost
-n|name name Database Name default:$USER
-o|output file Output file default:$output.dot
-p|port number TCP/IP port default:5432
-u|user name User name default:$USER
-v|version Display script version
EOT
} # ---------- end of function usage ----------
#-----------------------------------------------------------------------
# Handle command line arguments
#-----------------------------------------------------------------------
while getopts ":dh:n:o:p:u:v" opt
do
case $opt in
d|debug ) set -x ;;
h|host ) dbhost="$OPTARG" ;;
n|name ) dbname="$OPTARG" ;;
o|output ) output="$OPTARG" ;;
p|port ) dbport=$OPTARG ;;
u|user ) dbuser=$OPTARG ;;
v|version ) echo "$0 -- Version $ScriptVersion"; exit 0 ;;
\? ) echo -e "\n Option does not exist : $OPTARG\n"
usage; exit 1 ;;
esac # --- end of case ---
done
shift $(($OPTIND-1))
[[ -f "$output" ]] && rm "$output"
tee "$output" <<eof< span="">
digraph g {
node [shape=rectangle]
rankdir=LR
EOF
psql -h $dbhost -U $dbuser -d $dbname -p $dbport -qtAf cte.sql |
sed -e 's/^/node/' -e 's/.*(null)|/node/' -e 's/^/\t/' -e 's/|[[:digit:]]*$//' |
sed -e 's/|/ -> node/' | tee -a "$output"
tee -a "$output" <<eof< span="">
}
EOF
dot -Tpng "$output" > "${output/dot/png}"
[[ -f "$output" ]] && rm "$output"
open "${output/dot/png}"</eof<></eof<>This script requires this SQL statement in a file called cte.sql
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT parent_id, id, recursion_level FROM a;Then you invoke it like this:
chmod +x pggraph
./pggraphAnd you will see the resulting graph.


INSERT INTO person (id, parent_id) VALUES (6,2);Run the utility again, and see the immediate changes to your directed graph:

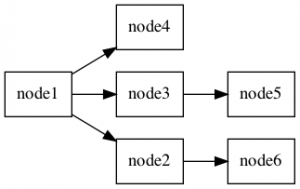
Now, that wasn’t so hard now, was it?