Tables and indexes vs. HDD and SSD

Although in the future most database servers (particularly those handling OLTP-like workloads) will use a flash-based storage, we’re not there yet – flash storage is still considerably more expensive than traditional hard drives, and so many systems use a mix of SSD and HDD drives. That however means we need to decide how to split the database – what should go to the spinning rust (HDD) and what is a good candidate for the flash storage that is more expensive but much better at handling random I/O.
There are solutions that try to handle this automatically at the storage level by automatically using SSDs as a cache, automatically keeping the active part of the data on SSD. Storage appliances / SANs often do this internally, there are hybrid SATA/SAS drives with large HDD and small SSD in a single package, and of course are solutions to do this at the host directly – for example there’s dm-cache in Linux, LVM also got such capability (built on top of dm-cache) in 2014, and of course ZFS has L2ARC.
But let’s ignore all of those automatic options, and let’s say we have two devices attached directly to the system – one based on HDDs, the other one flash-based. How should you split the database to get the most benefit of the expensive flash? One commonly used pattern is to do this by object type, particularly tables vs. indexes. Which makes sense in general, but we often see people placing indexes on the SSD storage, as indexes are associated with random I/O. While this may seem reasonable, it turns out this is exactly the opposite of what you should be doing.
Let me show you a benchmark …
Let me demonstrate this on a system with both HDD storage (RAID10 built from 4x 10k SAS drives) and a single SSD device (Intel S3700). The system has 16GB of RAM, so let’s use pgbench with scales 300 (=4.5GB) and 3000 (=45GB), i.e. one that easily fits into RAM and a multiple of RAM. Then let’s place tables and indexes on different storage systems (by using tablespaces), and measure the performance. The database cluster was reasonably configured (shared buffers, WAL limits etc.) with respect to the hardware resources. The WAL was placed on a separate SSD device, attached to a RAID controller shared with the SAS drives.
On the small (4.5GB) data set, the results look like this (notice the y-axis starts at 3000 tps):
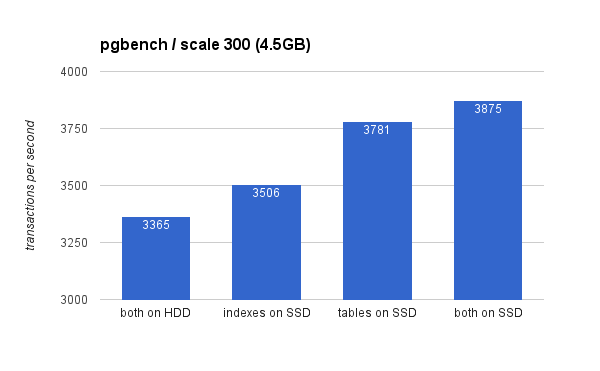
Clearly, placing the indexes on SSD gives lower benefit compared to using the SSD for tables. While the dataset easily fits into RAM, the changes need to eventually written to disk eventually, and while the RAID controller has a write cache, it can’t really compete with the flash storage. New RAID controllers would probably perform a bit better, but so would new SSD drives.
On the large data set, the differences are much more significant (this time y-axis starts at 0):
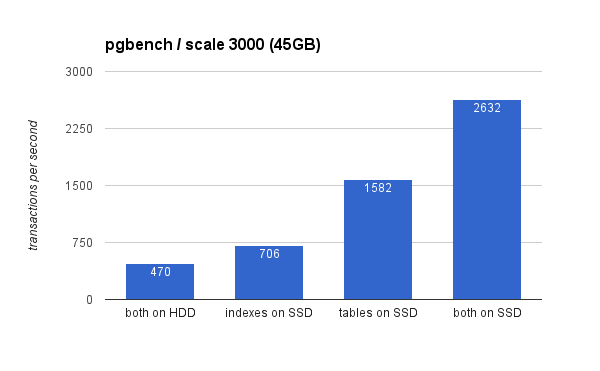
Placing the indexes on SSD results in significant performance gain (almost 50%, taking HDD storage as a baseline), but moving tables to the SSD easily beat that by gaining more than 200%. Of course, if you place both tables and index on SSDs, you’ll get improve the performance further – but if you could do that, you don’t need to worry about the other cases.
But why?
Getting better performance from placing tables on SSDs may seems a bit counter-intuitive, so why does it behave like this? Well, it’s probably a combination of several factors:
- indexes are usually much smaller than tables, and thus fit into memory more easily
- the pages in levels of indexes (in the tree) are usually quite hot, and thus remain in memory
- when scanning and index, a lot of the actual I/O is sequential in nature (particularly for leaf pages)
The consequence of this is that a surprising amount of I/O against indexes either does not happen at all (thanks to caching) or is sequential. On the other hand, indexes are a great source of random I/O against the tables.
It’s more complicated, though …
Of course, this was a just a simple example, and the conclusions might be different for substantially different workloads, for example. Similarly, as SSDs are more expensive, systems tend to have more disk space on HDD drives than on SSD drives, so tables may not fit onto the SSD while indexes would. In those cases a more elaborate placement is necessary – for example considering not just the type of the object, but also how often it’s used (and only moving the heavily used tables to SSDs), or even subsets of tables (e.g. by gradually moving old data from SSD to HDD).