On the benefits of sorted paths

I had the pleasure to attend PGDay UK last week – a very nice event, hopefully I’ll have the chance to come back next year. There was plenty of interesting talks, but the one that caught my attention in particular was Performace for queries with grouping by Alexey Bashtanov.
I have given a fair number of similar performance-oriented talks in the past, so I know how difficult it is to present benchmark results in a comprehensible and interesting way, and Alexey did a pretty good job, I think. So if you deal with data aggregation (i.e. BI, analytics, or similar workloads) I recommend going through the slides and if you get a chance to attend the talk on some other conference, I highly recommend doing so.
But there’s one point where I disagree with the talk, though. On a number of places the talk suggested that you should generally prefer HashAggregate, because sorts are slow.
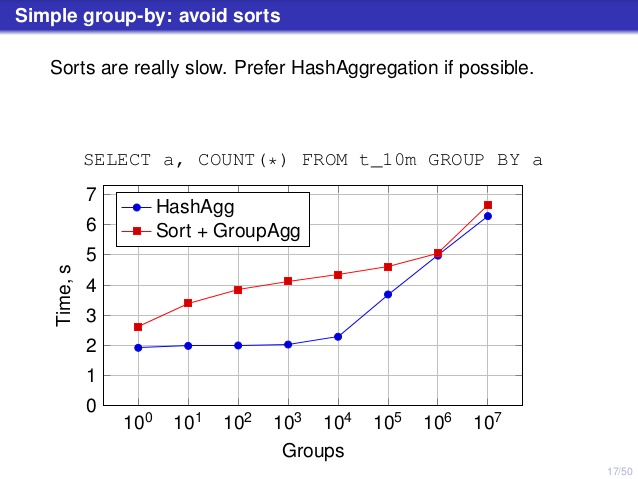
I consider this a bit misleading, because an alternative to HashAggregate is GroupAggregate, not Sort. So the recommendation assumes that each GroupAggregate has a nested Sort, but that’s not quite true. GroupAggregate requires sorted input, and an explicit Sort is not the only way to do that – we also have IndexScan and IndexOnlyScan nodes, that eliminate the sort costs and keep the other benefits associated with sorted paths (especially IndexOnlyScan).
Let me demonstrate how (IndexOnlyScan+GroupAggregate) performs compared to both HashAggregate and (Sort+GroupAggregate) – the script I’ve used for the measurements is here. It builds four simple tables, each with 100M rows and different number of groups in the “branch_id” column (determining the size of the hash table). The smallest one has 10k groups
-- table with 10k groups
create table t_10000 (branch_id bigint, amount numeric);
insert into t_10000 select mod(i, 10000), random()
from generate_series(1,100000000) s(i);and three additional tables have 100k, 1M and 5M groups. Let’s run this simple query aggregating the data:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1and then convince the database to use three different plans:
1) HashAggregate
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows)2) GroupAggregate (with a Sort)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows)3) GroupAggregate (with an IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows)Results
After measuring timings for each plan on all the tables, the results look like this:
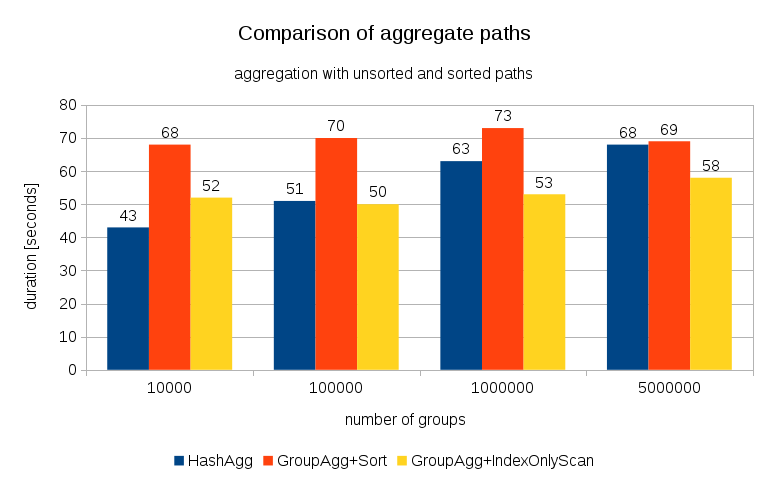
For small hash tables (fitting into L3 cache, which is 16MB in this case), HashAggregate path is clearly faster than both sorted paths. But pretty soon GroupAgg+IndexOnlyScan gets just as fast or even faster – this is due to cache efficiency, the main advantage of GroupAggregate. While HashAggregate needs to keep the whole hash table in memory at once, GroupAggregate only needs to keep the last group. And the less memory you use, the more likely it’s to fit that into L3 cache, which is roughly an order of magnitude faster compared to regular RAM (for the L1/L2 caches the difference is even larger).
So although there’s a considerable overhead associated with IndexOnlyScan (for the 10k case it’s about 20% slower than the HashAggregate path), as the hash table grows the L3 cache hit ratio quickly drops and the difference eventually makes the GroupAggregate faster. And eventually even the GroupAggregate+Sort gets on par with the HashAggregate path.
You might argue that your data generally have fairly low number of groups, and thus the hash table will always fit into L3 cache. But consider that the L3 cache is shared by all processes running on the CPU, and also by all parts of the query plan. So although we currently have ~20MB of L3 cache per socket, your query will only get a part of that, and that bit will be shared by all nodes in your (possibly quite complex) query.
Update 2016/07/26: As pointed out in the comments by Peter Geoghegan, the way the data was generated probably results in correlation – not the values (or rather hashes of the values), but memory allocations. I’ve repeated the queries with properly randomized data, i.e. doing
insert into t_10000 select (10000*random())::bigint, random()
from generate_series(1,100000000) s(i);instead of
insert into t_10000 select mod(i, 10000), random()
from generate_series(1,100000000) s(i);and the results look like this:
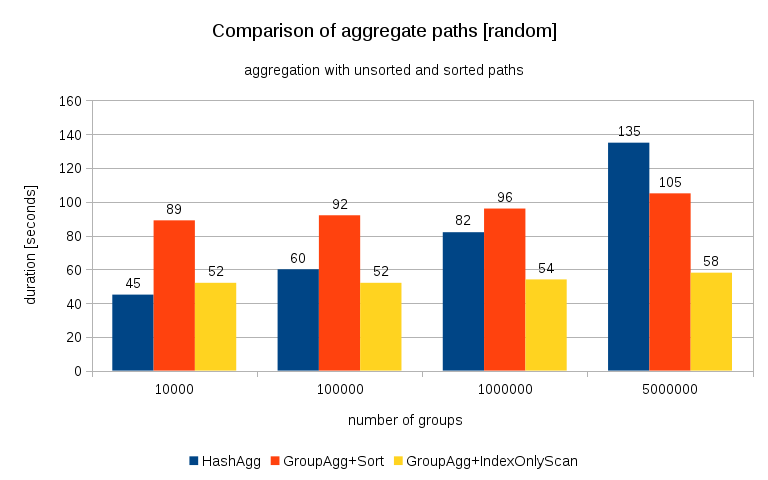
Comparing this with the previous chart, I think it’s pretty clear the results are even more in favor of sorted paths, particularly for the data set with 5M groups. The 5M data set also shows that GroupAgg with an explicit Sort may be faster than HashAgg.
Summary
While HashAggregate is probably faster than GroupAggregate with an explicit Sort (I’m hesitant to say it’s always the case, though), using GroupAggregate with IndexOnlyScan faster can easily make it much faster than HashAggregate.
Of course, you don’t get to pick the exact plan directly – the planner should do that for you. But you affect the selection process by (a) creating indexes and (b) setting work_mem. Which is why sometimes lower work_mem (and maintenance_work_mem) values result in better performance.
Additional indexes are not free, though – they cost both CPU time (when inserting new data), and disk space. For IndexOnlyScans the disk space requirements may be quite significant because the index needs to include all the columns referenced by the query, and regular IndexScan would not give you the same performance as it generates a lot of random I/O against the table (eliminating all the potential gains).
Another nice feature is the stability of the performance – notice how the HashAggregate timings chance depending on the number of groups, while the GroupAggregate paths perform mostly the same.