Getting WAL files from Barman with 'get-wal'

Barman 1.5.0 enhances the robustness and business continuity capabilities of PostgreSQL clusters, integrating the get-wal command with any standby server’s restore_command.
In this blog article I will go over the reasons behind this feature and briefly describe it.
One of the initial ideas we had in mind when conceiving Barman was to make it, one day, a very large basin of WAL files, collected from one or more PostgreSQL servers within the same organisation.
The internal codename of this feature was “WAL hub” and, in our mind, its main purpose was to allow any application (e.g. standby) to easily request and receive any WAL file for a given server, by enhancing Barman’s command line interface and, ultimately, by implementing server support for PostgreSQL’s streaming replication.
The first leg of this journey has now been reached, and it is part of Barman 1.5.0: the get-wal command.
Firstly, why would such a feature be needed?
Barman currently supports only WAL shipping from the master using archive_command (Postgres 9.5 will allow users to ship WAL files from standby servers too through “archive_mode = always” and we’ll be thinking of something for the next Barman release).
However, very frequently we see users that prefer to ship WAL files from Postgres to multiple locations, such as one or more standby servers or another file storage destination.
In these cases, the logic of these archive command scripts can easily become quite complex and, in the long term, dangerously slip through your grasp (especially if PostgreSQL and its operating system are not under strict monitoring).
Also, if you too are a long time user of PostgreSQL, you are probably empathising with me while remembering the “pre-9.0 era” when file-based log shipping was the only available option for replication.
Nowadays, on the contrary, the amount of possibilities you have in terms of design of PostgreSQL architectures in business continuity environments is practically endless, as you can combine native features such as streaming replication (both asynchronous and synchronous), asynchronous WAL archiving, cascading replication, replication slots, etc.
NOTE: I want to emphasise on the word native, as all of this is available in “Pure PostgreSQL”, the 100% open source PostgreSQL maintained and distributed by our fantastic Community.
With 1.5.0 you can even integrate Barman with a standby server’s restore_command, adding a fallback method to streaming replication synchronisation, to be used in case of temporary (or not) network issues with the source of the stream (be it a master or another standby).
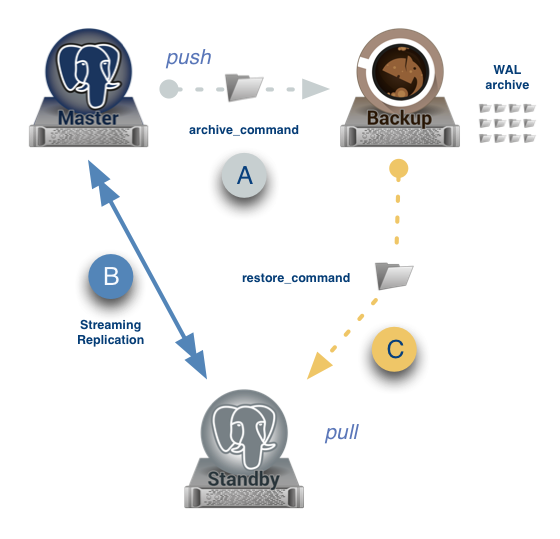
In the above figure, I have depicted a very simple scenario of how get-wal can improve the robustness of any PostgreSQL replica, in just three steps:
- your PostgreSQL master server is configured to ship WAL files to Barman (process “A”), with
archive_command; - through Barman,
pg_basebackupor repmgr, you initialise a standby server and then start the streaming replication process with the master (process “B”); - you configure the standby server to use
restore_commandin conjunction with Barman’sget-walandssh, and take advantage of the aforementioned fallback technique (process “C”).
This technique can be a life saver when your streaming replication standby server, for example for maintenance reasons, needs to be shut down for several hours or even a few days and, when you start it up you get an unpleasant message like this:
FATAL: could not receive data from WAL stream:
FATAL: requested WAL segment 00000002000009AE0000000B has
already been removed
All you are left to do is to re-clone the standby which, in some cases, can be a painful and extremely long operation (depending on the size of your cluster and on how your system performs).
You can certainly use replication slots or keep a high value for wal_keep_segments. A third and, in my opinion, more robust, cost-effective and resilient option is to take advantage of the existing Barman node that you have installed in your environment.
Indeed, the assumption is that Barman is there already, for backup and disaster recovery purposes. Its aim is to retain as much history as possible of your PostgreSQL server, in order to be able and recover at any point in time between the first available backup and now.
It is a business continuity requirement that is fulfilled by Barman and easily defined through retention policies, so that you specify the number of backups you want to keep or the recovery time frame (e.g. last 3 MONTHS).
Therefore, WAL files are already there, in your organisation’s Barman node, and now, thanks to get-wal you can configure a standby to automatically get them, on-demand, when needed, as a PULL system.
All you have to do is add this line in the standby’s recovery.conf file:
# Change 'SERVER' with the actual ID of the server in Barman
restore_command = 'ssh barman@pgbackup barman get-wal SERVER %f > %p'
You can get inspired by barman-wal-restore, a more resilient shell script distributed along Barman, which also manages ssh connection errors (including the unpleasant exit code 255).
NOTE: This configuration implies that the
postgresuser can connect via ssh to the Barman server asbarmanuser, through public key exchange.
With such new scenario, when the standby is not able to get WAL data through the streaming replication protocol, the fallback method kicks in: Postgres executes the restore_command which remotely fetches the required WAL file from Barman.
An important aspect of this action is that Barman transparently handles decompression of the WAL file – as usually WAL files are compressed inside Barman’s archive.
For more information on the get-wal command, you can read the man page on the documentation website, or type any (or both):
man barman
barman get-wal help
As you have already guessed, this is probably one of my favourite features that has ever been brought into Barman, as it is the first important stage towards a more organic integration with Postgres replication systems, starting from his big brother: repmgr.
The above example is just one possible architecture. Your challenge is to understand the needs of your organisation and contextualise what Postgres and Barman can offer for your specific environment – which is different from any other.
As a final note, my view is that Barman is another blade of our Postgres Swiss Army knife. More widely, this concept applies to Open Source Software in general, not just PostgreSQL.
So, all we have to do now is think like MacGyver, improvise and … have fun! 😉