Global Deadlock and Detection in Local PostgreSQL Database

Nowadays, typical production databases do not consist of a single database. Typically, they consist of multiple databases, connected to each other by streaming replication, logical replication, BDR, FDW, and other application-specific data replication and distribution.
At present, most application workloads target a single database at a time and, therefore, distributed transactions behavior is not a serious issue, fortunately.
In the future, more workloads are expected to target multiple databases, and the database kernel may need to provide additional features.
Global deadlock is a phenomenon that current single databases cannot detect. This new blog series will provide information on what deadlock is, how it is handled currently in PostgreSQL, and what additional features you should provide in such a distributed environment.
To start, this blog post describes what global deadlock is and how it is handled in current PostgreSQL. Handling deadlock in a distributed environment will be reviewed afterwards.
What is deadlock?
To protect the data a transaction (or process) is handling, you can use a lock. A lock is a mechanism to prevent target data updated or deleted in an undesirable way. If other transactions would like to acquire a lock and it conflicts, the transaction waits until the lock is released, as seen in Figure 1.
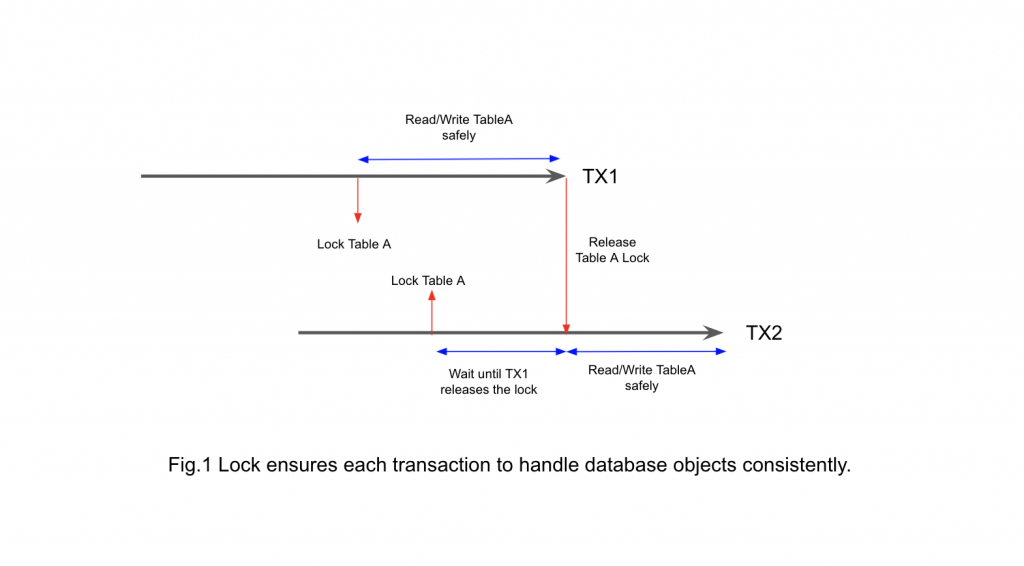
Usually lock has more than one mode, and some lock modes allow more than one transaction to acquire a lock. Other lock modes allow only one transaction to acquire a lock. In typical databases including PostgreSQL, such locks are released only when the holding transaction ends with commit or abort. This is called Two-Phase Locking (2PL, note that this is different from two-phase-commit, 2PC) and is necessary to ensure transaction serializability.
In some situations, there’s a chance that two transactions wait for each other.
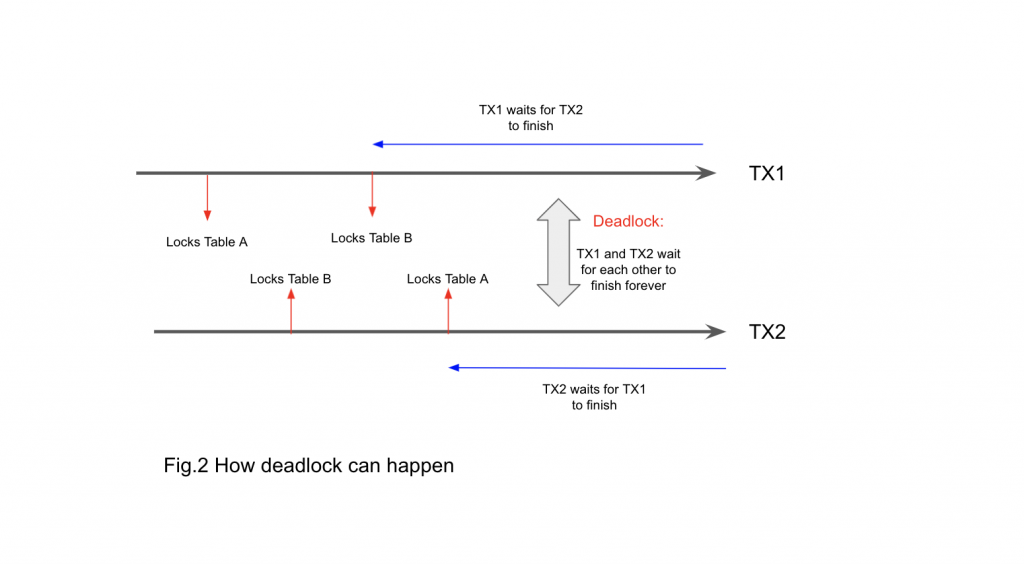 As in Figure 2, transaction (T1) acquires an exclusive lock on a table (TabA) and another transaction (T2) acquires an exclusive lock on another table (TabB). Then, T1 tries to acquire an exclusive lock on TabB. T1 then starts to wait for T2 to finish. After this, assume that T2 tries to acquire an exclusive lock on TabA.
As in Figure 2, transaction (T1) acquires an exclusive lock on a table (TabA) and another transaction (T2) acquires an exclusive lock on another table (TabB). Then, T1 tries to acquire an exclusive lock on TabB. T1 then starts to wait for T2 to finish. After this, assume that T2 tries to acquire an exclusive lock on TabA.
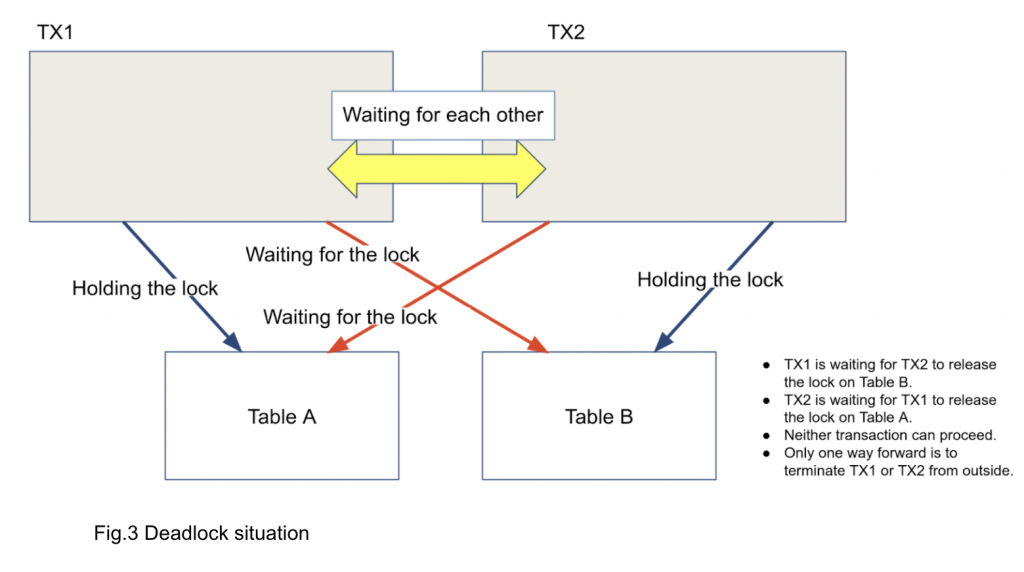
In this situation, T1 is waiting for T2 and T2 is waiting for T1 (Figure 3). There's no way to proceed unless you terminate T1 or T2 from outside.
This situation is called a deadlock. Figure 3 represents the simplest deadlock scenario, and the situation can be much more complicated in reality. Within the database kernel, internal lock strategy is carefully designed to prevent such scenarios. However, deadlock can occur only by application workload and it is not possible to prevent such a scenario to happen in general.
Why deadlock detection is needed
It looks as though transaction timeout may work to resolve the deadlock so that transactions running too long are aborted. It is quite difficult to set up a successful timeout, especially for a large batch. Transaction duration depends upon other workloads and it is not a comfortable situation—a batch transaction aborts it after several hours of running without any deadlock or potential issues. It is best to detect deadlocks and keep other healthy transactions running. Even though deadlocks are detected, only one transaction involved is killed and all the other transactions can keep running.
Steps to detect the deadlock
Many database textbooks describe how to detect the deadlock. To detect the deadlock, we use the wait-for-graph approach. This is the simple and established way.
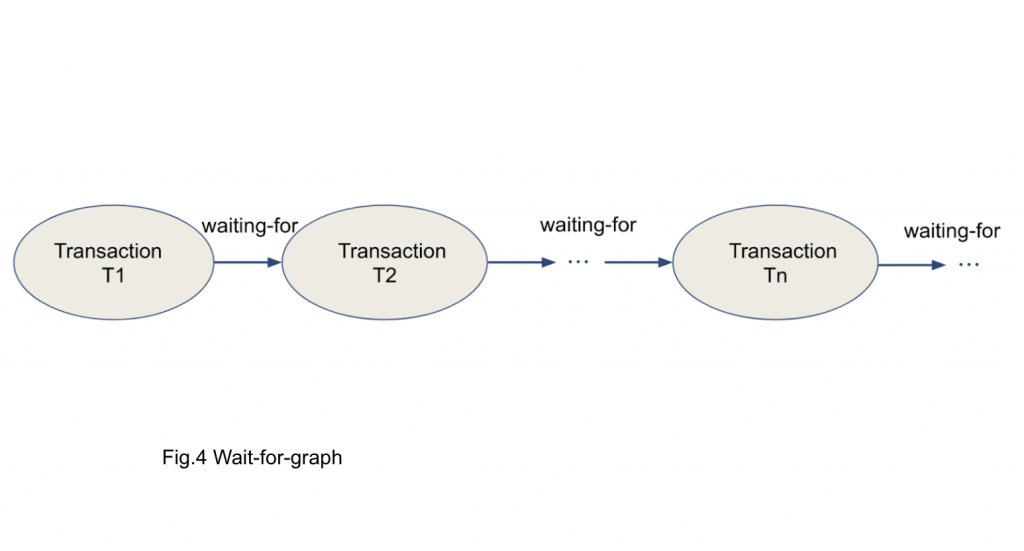
To detect a deadlock, you can analyze which transaction is waiting for what. Figure 4 is a very simple wait-for-graph.
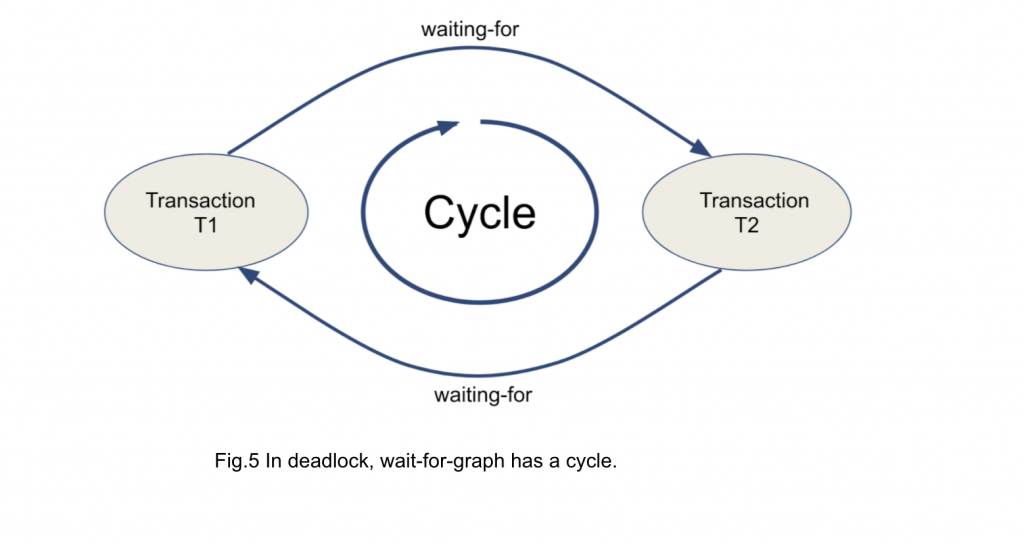
It is also known that the wait-for-graph contains a "cycle" when a deadlock occurs as [1][2][3][4] as illustrated in Figure 5. You can use this cycle in a wait-for-graph to detect a deadlock.
In PostgreSQL, when a transaction cannot acquire the requested lock within a certain amount of time (configured by `deadlock_timeout`, with default value of 1 second), it begins deadlock detection.
Starting with the transaction that failed to acquire a lock, PG checks (more than one) transactions holding the lock originating transaction is waiting. Then, PG checks if transactions are waiting for another lock. By repeating this, you can construct a wait-for-graph. PG searches all the possible wait-for-graph segments until the graph ends with a transaction waiting for no lock, or it finds a "cycle," where the graph reaches the same transaction at the beginning of the graph.
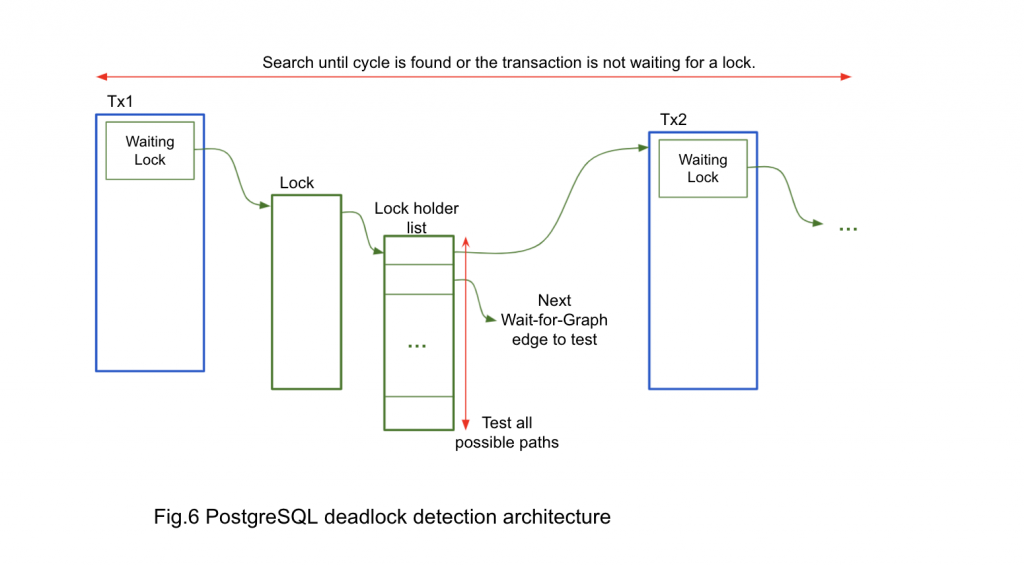 Figure 6 shows a simple and schematic description of this.
Figure 6 shows a simple and schematic description of this.
Global deadlock scenario
Similar situations can happen in multi-database (or distributed database) environments where a transaction spans across more than one database. This is called "global deadlock."
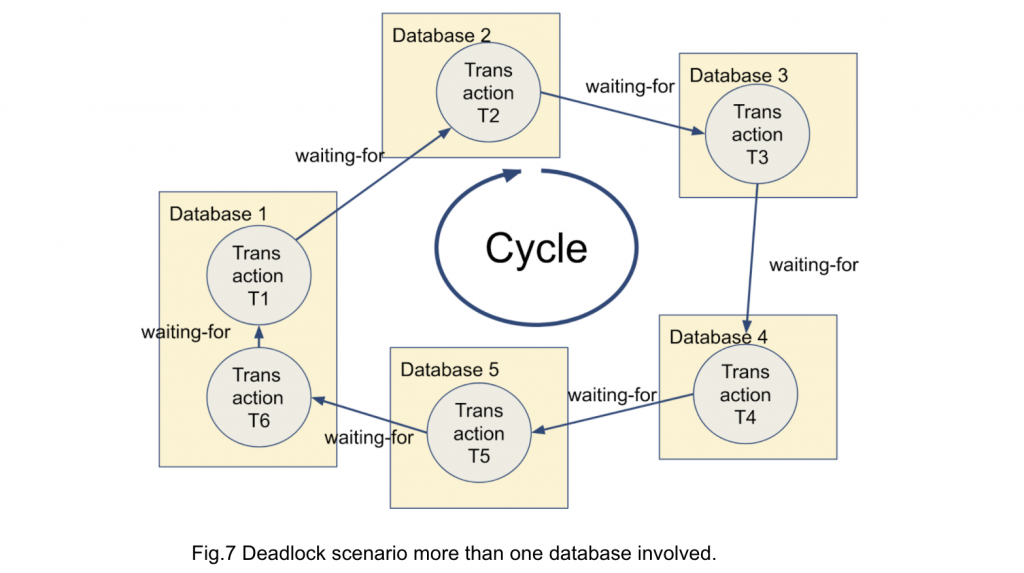
Figure 7 shows a bit more complicated global deadlock scenario. Please note that a global deadlock scenario can involve three or more databases, and wait-for-graph can go out to the other database, come back, then go further to another database. The scenario can be very complicated.
In such a situation in current PG, a transaction waiting for remote transactions is not waiting for any lock, and you have no means to trace such cluster-wide wait-for-graph.
It is also known that even in such a distributed transaction, you can use cluster wide wait-for-graph to detect a global deadlock [2][4].
What's next?
In the next post of this series, I will show how you can use and extend current PostgreSQL deadlock detection to detect such global deadlock. Stay tuned!
References
[1] P.A.Bernstein et al., "Concurrency Control and Recovery in Database Systems", 1987, Addison Wesley
[2] J.Gray et al., "Transaction Processing: Concepts and Techniques", 1993, Morgan Kaufmann
[3] H.Garcia-Morina et al., "Database Systems - the Complete Book", 2002, Prentice Hall
[4] M.T.Ozsu et al., "Principles of Distributed Database Systems, 4th Ed.", 2020, Springer