How to Automate PostgreSQL 12 Replication and Failover with repmgr - Part 2


This is the second installment of a two-part series on 2ndQuadrant’s repmgr, an open-source high-availability tool for PostgreSQL.
In the first part, we set up a three-node PostgreSQL 12 cluster along with a “witness” node. The cluster consisted of a primary node and two standby nodes. The cluster and the witness node were hosted in an Amazon Web Service Virtual Private Cloud (VPC). The EC2 servers hosting the Postgres instances were placed in subnets in different availability zones (AZ), as shown below:
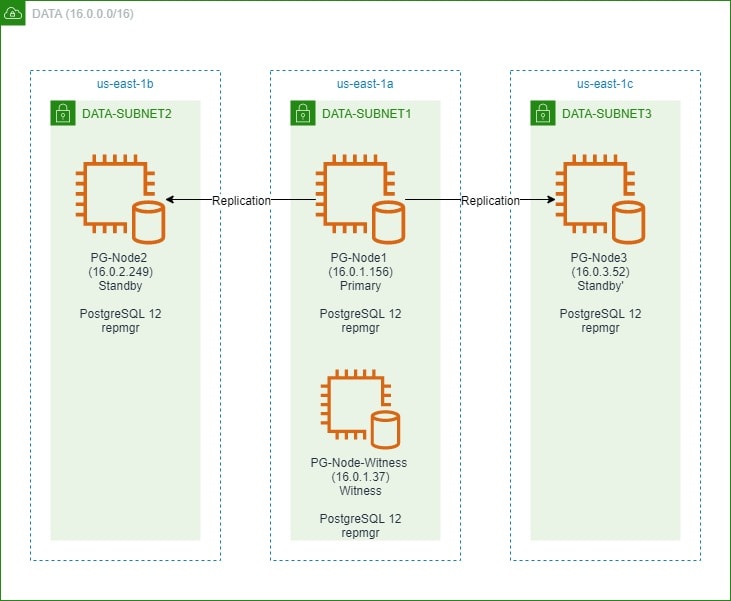
We will make extensive references to the node names and their IP addresses, so here is the table again with the nodes’ details:
| Node Name | IP Address | Role | Apps Running |
| PG-Node1 | 16.0.1.156 | Primary | PostgreSQL 12 and repmgr |
| PG-Node2 | 16.0.2.249 | Standby 1 | PostgreSQL 12 and repmgr |
| PG-Node3 | 16.0.3.52 | Standby 2 | PostgreSQL 12 and repmgr |
| PG-Node-Witness | 16.0.1.37 | Witness | PostgreSQL 12 and repmgr |
We installed repmgr in the primary and standby nodes and then registered the primary node with repmgr. We then cloned both the standby nodes from the primary and started them. Both the standby nodes were also registered with repmgr. The “repmgr cluster show” command showed us everything was running as expected:

Current Problem
Setting up streaming replication with repmgr is very simple. What we need to do next is to ensure the cluster will function even when the primary becomes unavailable. This is what we will cover in this article.
In PostgreSQL replication, a primary can become unavailable for a few reasons. For example:
- The operating system of the primary node can crash, or become unresponsive
- The primary node can lose its network connectivit
- The PostgreSQL service in the primary node can crash, stop, or become unavailable unexpectedly
- The PostgreSQL service in the primary node can be stopped intentionally or accidentally
Whenever a primary becomes unavailable, a standby does not automatically promote itself to the primary role. A standby still continues to serve read-only queries – although the data will be current up to the last LSN received from the primary. Any attempt for a write operation will fail.
There are two ways to mitigate this:
- The standby is manually upgraded to a primary role. This is usually the case for a planned failover or “switchover”
- The standby is automatically promoted to a primary role. This is the case with non-native tools that continuously monitor replication and take recovery action when the primary is unavailable. repmgr is one such tool.
We will consider the second scenario here. This situation has some extra challenges though:
- If there are more than one standbys, how does the tool (or the standbys) decide which one is to be promoted as primary? How does the quorum and the promotion process work?
- For multiple standbys, if one is made primary, how do the other nodes start “following it” as the new primary?
- What happens if the primary is functioning, but for some reason temporarily detached from the network? If one of the standbys is promoted to primary and then the original primary comes back online, how can a “split brain” situation be avoided?
remgr’s Answer: Witness Node and the repmgr Daemon
To answer these questions, repmgr uses something called a witness node. When the primary is unavailable – it is the witness node’s job to help the standbys reach a quorum if one of them should be promoted to a primary role. The standbys reach this quorum by determining if the primary node is actually offline or only temporarily unavailable. The witness node should be located in the same data centre/network segment/subnet as the primary node, but must NEVER run on the same physical host as the primary node.
Remember that in the first part of this series, we rolled out a witness node in the same availability zone and subnet as the primary node. We named it PG-Node-Witness and installed a PostgreSQL 12 instance there. In this post, we will install repmgr there as well, but more on that later.
The second component of the solution is the repmgr daemon (repmgrd) running in all nodes of the cluster and the witness node. Again, we did not start this daemon in the first part of this series, but we will do so here. The daemon comes as part of the repmgr package – when enabled, it runs as a regular service and continuously monitors the cluster’s health. It initiates a failover when a quorum is reached about the primary being offline. Not only can it automatically promote a standby, it can also reinitiate other standbys in a multi-node cluster to follow the new primary.
The Quorum Process
When a standby realizes it cannot see the primary, it consults with other standbys. All the standbys running in the cluster reach a quorum to choose a new primary using a series of checks:
- Each standby interrogates other standbys about the time it last “saw” the primary. If a standby’s last replicated LSN or the time of last communication with the primary is more recent than the current node’s last replicated LSN or the time of last communication, the node does not do anything and waits for the communication with the primary to be restored
- If none of the standbys can see the primary, they check if the witness node is available. If the witness node cannot be reached either, the standbys assume there is a network outage on the primary side and do not proceed to choose a new primary
- If the witness can be reached, the standbys assume the primary is down and proceed to choose a primary
- The node that was configured as the “preferred” primary will then be promoted. Each standby will have its replication reinitialized to follow the new primary.
Configuring the Cluster for Automatic Failover
We will now configure the cluster and the witness node for automatic failover.
Step 1: Install and Configure repmgr in Witness
We already saw how to install the repmgr package in our last article. We do this in the witness node as well:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpmAnd then:
# yum install repmgr12 -yNext, we add the following lines in the witness node’s postgresql.conf file:
listen_addresses = '*'
shared_preload_libraries = 'repmgr'We also add the following lines in the pg_hba.conf file in the witness node. Note how we are using the CIDR range of the cluster instead of specifying individual IP addresses.
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 16.0.0.0/16 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 16.0.0.0/16 trustNote
[The steps described here are for demonstration purposes only. Our example here is using externally reachable IPs for the nodes. Using listen_address = ‘*’ along with pg_hba’s “trust” security mechanism therefore poses a security risk, and should NOT be used in production scenarios. In a production system, the nodes will all be inside one or more private subnets, reachable via private IPs from jumphosts.]
With postgresql.conf and pg_hba.conf changes done, we create the repmgr user and the repmgr database in the witness, and change the repmgr user’s default search path:
[postgres@PG-Node-Witness ~]$ createuser --superuser repmgr
[postgres@PG-Node-Witness ~]$ createdb --owner=repmgr repmgr
[postgres@PG-Node-Witness ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"Finally, we add the following lines to the repmgr.conf file, located under /etc/repmgr/12/
node_id=4
node_name='PG-Node-Witness'
conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/var/lib/pgsql/12/data'Once the config parameters are set, we restart the PostgreSQL service in the witness node:
# systemctl restart postgresql-12.serviceTo test the connectivity to witness node repmgr, we can run this command from the primary node:
[postgres@PG-Node1 ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'Next, we register the witness node with repmgr by running the “repmgr witness register” command as the postgres user. Note how we are using the address of the primary node, and NOT the witness node in the command below:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156This is because the “repmgr witness register” command adds the witness node’s metadata to primary node’s repmgr database, and if necessary, initialises the witness node by installing the repmgr extension and copying the repmgr metadata to the witness node.
The output will look like this:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4)
INFO: connecting to primary node
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
INFO: witness registration complete
NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registeredFinally, we check the status of the overall setup from any node:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compactThe output looks like this:

Step 2: Modifying the sudoers File
With the cluster and the witness running, we add the following lines in the sudoers file In each node of the cluster and the witness node:
Defaults:postgres !requiretty
postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.serviceStep 3: Configuring repmgrd Parameters
We have already added four parameters in the repmgr.conf file in each node. The parameters added are the basic ones needed for repmgr operation. To enable the repmgr daemon and automatic failover, a number of other parameters need to be enabled/added. In the following subsections, we will describe each parameter and the value they will be set to in each node.
failover
The failover parameter is one of the mandatory parameters for the repmgr daemon. This parameter tells the daemon if it should initiate an automatic failover when a failover situation is detected. It can have either of two values: “manual” or “automatic”. We will set this to automatic in each node:
failover='automatic'promote_command
This is another mandatory parameter for the repmgr daemon. This parameter tells the repmgr daemon what command it should run to promote a standby. The value of this parameter will be typically the “repmgr standby promote” command, or the path to a shell script that calls the command. For our use case, we set this to the following in each node:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'follow_command
This is the third mandatory parameter for the repmgr daemon. This parameter tells a standby node to follow the new primary. The repmgr daemon replaces the %n placeholder with the node ID of the new primary at run time:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'priority
The priority parameter adds weight to a node’s eligibility to become a primary. Setting this parameter to a higher value gives a node greater eligibility to become the primary node. Also, setting this value to zero for a node will ensure the node is never promoted as primary.
In our use case, we have two standbys: PG-Node2 and PG-Node3. We want to promote PG-Node2 as the new primary when PG-Node1 goes offline, and PG-Node3 to follow PG-Node2 as its new primary. We set the parameter to the following values in the two standby nodes:
| Node Name | Parameter Setting |
| PG-Node2 | priority=60 |
| PG-Node3 | priority=40 |
monitor_interval_secs
This parameter tells the repmgr daemon how often (in number of seconds) it should check the availability of the upstream node. In our case, there is only one upstream node: the primary node. The default value is 2 seconds, but we will explicitly set this anyhow in each node:
monitor_interval_secs=2connection_check_type
The connection_check_type parameter dictates the protocol repmgr daemon will use to reach out to the upstream node. This parameter can take three values:
- ping: repmgr uses the PQPing() method
- connection: repmgr tries to create a new connection to the upstream node
- query: repmgr tries to run a SQL query on the upstream node using the existing connection
Again, we will set this parameter to the default value of ping in each node:
connection_check_type='ping'reconnect_attempts and reconnect_interval
When the primary becomes unavailable, the repmgr daemon in the standby nodes will try to reconnect to the primary for reconnect_attempts times. The default value for this parameter is 6. Between each reconnect attempt, it will wait for reconnect_interval seconds, which has a default value of 10. For demonstration purposes, we will use a short interval and fewer reconnect attempts. We set this parameter in every node:
reconnect_attempts=4
reconnect_interval=8primary_visibility_consensus
When the primary becomes unavailable in a multi-node cluster, the standbys can consult each other to build a quorum about a failover. This is done by asking each standby about the time it last saw the primary. If a node’s last communication was very recent and later than the time the local node saw the primary, the local node assumes the primary is still available, and does not go ahead with a failover decision.
To enable this consensus model, the primary_visibility_consensus parameter needs to be set to “true” in each node – including the witness:
primary_visibility_consensus=truestandby_disconnect_on_failover
When the standby_disconnect_on_failover parameter is set to “true” in a standby node, the repmgr daemon will ensure its WAL receiver is disconnected from the primary and not receiving any WAL segments. It will also wait for the WAL receivers of other standby nodes to stop before making a failover decision. This parameter should be set to the same value in each node. We are setting this to “true”.
standby_disconnect_on_failover=trueSetting this parameter to true means every standby node has stopped receiving data from the primary as the failover happens. The process will have a delay of 5 seconds plus the time it takes the WAL receiver to stop before a failover decision is made. By default, the repmgr daemon will wait for 30 seconds to confirm all sibling nodes have stopped receiving WAL segments before the failover happens.
repmgrd_service_start_command and repmgrd_service_stop_command
These two parameters specify how to start and stop the repmgr daemon using the “repmgr daemon start” and “repmgr daemon stop” commands.
Basically, these two commands are wrappers around operating system commands for starting/stopping the service. The two parameter values map these commands to their OS-specific versions. We set these parameters to the following values in each node:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service'
repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'PostgreSQL Service Start/Stop/Restart Commands
As part of its operation, the repmgr daemon will often need to stop, start or restart the PostgreSQL service. To ensure this happens smoothly, it is best to specify the corresponding operating system commands as parameter values in the repmgr.conf file. We will set four parameters in each node for this purpose:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service'
service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service'
service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service'
service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'monitoring_history
Setting the monitoring_history parameter to “yes” will ensure repmgr is saving its cluster monitoring data. We set this to “yes” in each node:
monitoring_history=yeslog_status_interval
We set the parameter in each node to specify how often the repmgr daemon will log a status message. In this case, we are setting this to every 60 seconds:
log_status_interval=60Step 4: Starting the repmgr Daemon
With the parameters now set in the cluster and the witness node, we execute a dry run of the command to start the repmgr daemon. We test this in the primary node first, and then the two standby nodes, followed by the witness node. The command has to be executed as the postgres user:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-runThe output should look like this:
INFO: prerequisites for starting repmgrd met
DETAIL: following command would be executed:
sudo /usr/bin/systemctl start repmgr12.serviceNext, we start the daemon in all four nodes:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon startThe output in each node should show the daemon has started:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service"
NOTICE: repmgrd was successfully startedWe can also check the service startup event from the primary or standby nodes:
[postgres@PG-NodeX ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_startThe output should show the daemon is monitoring the connections:
Node ID | Name | Event | OK | Timestamp | Details
--------+-----------------+---------------+----+---------------------+------------------------------------------------------------------
4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1)
3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1)
2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1)
1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)Finally, we can check the daemon output from the syslog in any of the standbys:
# cat /var/log/messages | grep repmgr | lessHere is the output from PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf"
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"
Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3)
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping"
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1)
Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state
Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago
Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state
…
… Checking the syslog in the primary node shows a different type of output:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf"
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1)
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping"
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1)
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached
Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected
Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state
Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state
…
…Step 5: Simulating a Failed Primary
Now we will simulate a failed primary by stopping the primary node (PG-Node1). From the shell prompt of the node, we run the following command:
# systemctl stop postgresql-12.serviceThe Failover Process
Once the process stops, we wait for about a minute or two, and then check the syslog file of PG-Node2. The following messages are shown. For clarity and simplicity, we have color-coded groups of messages and added whitespaces between lines:
…
Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds
…
…
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2)
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes
…
…
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote()
Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode
Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2)
Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected
Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected
Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected
Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state
Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state
…
… There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
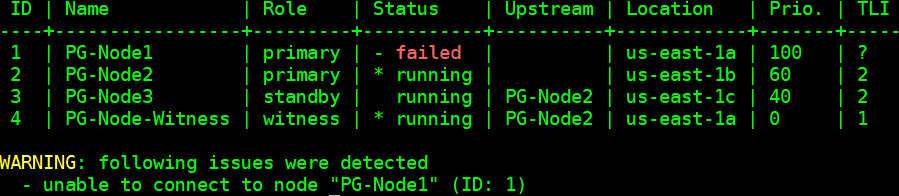
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[postgres@PG-Node-Witness ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compactThe output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[postgres@PG-Node2 ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster eventThe output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details
--------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------
3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2
3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2)
2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected
2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected
4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2)
4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2
2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2)
2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed
2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary
1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected Conclusion
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1