Incremental backup with Barman 1.4.0

Today version 1.4.0 of Barman has been officially released. The most important feature is incremental backup support, which relies on rsync and hard links and helps you reduce both backup time and disk space by 50-70%.
 Barman adds one configuration option, called
Barman adds one configuration option, called reuse_backup. By setting this option to link, Barman will transparently reuse the latest available backup in the catalogue of a given server when issuing a barman backup command.
“Mhh … hang on … Did you just say ‘Reuse’? In what terms?”
Essentially, Barman will reuse the previous backup in two phases:
- when reading the backup files;
- when permanently saving the backup files.
Barman simply exploits rsync’s robust and proven technology in order:
- to skip transferring those database files that have not changed from the latest base backup;
- use hard links on the backup side in order to save disk space (data deduplication).
If you happen to follow me on Twitter, you might have already seen this message about data deduplication on one of our customer’s database:
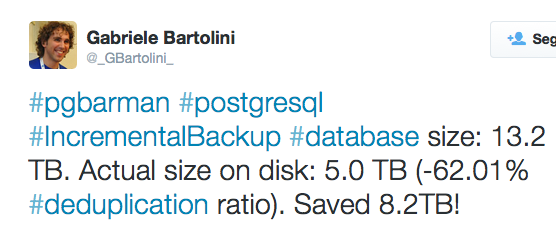 This particular case involves a very large database of 13.2 Terabyte. Consider doing a weekly backup of a 13.2 TB database. You face two major problems:
This particular case involves a very large database of 13.2 Terabyte. Consider doing a weekly backup of a 13.2 TB database. You face two major problems:
- backup time
- backup size (with a large impact on retention policies)
As you can see, over 8.2 TB of data had not changed between the two backups, with a subsequent reduction of both backup time (17 hours instead of more than 50!) and disk space (5TB instead of 13TB!), as well as network bandwidth (by the way, Barman allows you to enable network compression too).
I must confess that a 13TB database is quite an exceptional case. However, what we have witnessed so far, even on smaller (and much smaller) databases, is an almost constant deduplication ratio in all the backups that we are managing with 2ndQuadrant. On average, deduplication ratio is between 50% and 70%.
The experience gained on this topic by Barman’s development team won’t stop here. A similar approach is being followed by Marco Nenciarini in its attempt to introduce file level incremental backup in PostgreSQL 9.5 through streaming replication and pg_basebackup.
On a final note, I would like to thank BIJ12, Jobrapido, Navionics, Sovon Vogelonderzoek Nederland and Subito.it for their support towards this release.