Mastering Logical Replication

Migrate a PostgreSQL Cluster using PGLogical Replication to Native Logical Replication
Introduction
PostgreSQL’s evolution has introduced several enhancements in terms of available replication mechanisms. Among these replication methods, logical replication has gained significant attention due to its ability to replicate specific tables and even individual changes. The Two prominent approaches for configuring logical replication in PostgreSQL clusters are PGLogical and Native Logical Replication.
PGLogical was a popular solution for logical replication in PostgreSQL for many years, offering flexible object level replication, including support for multi-master configurations. However, with the introduction of Native Logical Replication in PostgreSQL 10, users have gained access to a more robust, built-in replication solution that offers simplified configuration, better performance, and direct support from the PostgreSQL community.
In this article, we will compare both PGLogical and Native Logical Replication to help you understand the key differences and guide you through the different steps of migrating a pglogical replication cluster to native logical replication in PostgreSQL. It assumes you are familiar with PostgreSQL administration and replication concepts, as well as the basic setup of pglogical. Choose the best solution for your specific use case.
Overview of PGLogical and Native Logical Replication
PGLogical
PGLogical is a third-party extension for PostgreSQL that implements logical replication. It is available since PostgreSQL 9.4 and provides advanced features beyond the capabilities of the native logical replication system, making it suitable for more complex replication scenarios. PGLogical is often used for heterogeneous replication (e.g., replication across different versions or clusters), DDL replication and multi-node replication with conflict resolution capabilities. However, as PostgreSQL continued to evolve, it introduced native support for logical replication, and with the more recent versions, it is making the pglogical extension redundant for many users.
Native Logical Replication
Introduced with PostgreSQL 10, Native logical replication allows asynchronous replication of data at the logical level, providing a flexible solution for replicating data between PostgreSQL instances. This system is built into the PostgreSQL core and with every new PostgreSQL version release, Native Logical replication is getting more and more new features and is now becoming the recommended approach for configuring object/database level replication in PostgreSQL clusters.
Key Differences Between pglogical and Native Logical Replication
| Features | pglogical Replication | Native Logical Replication |
|---|---|---|
| Built-in | External extension (requires installation) | Built into PostgreSQL (since version 10) |
| Replication Granularity | Supports Tables, Sequences, specific columns, row filtering | Supports Tables or schemas. Replication of specific columns and row filtering available since version 15 |
| Parallel Data sync | Not Supported | Parallel initial data sync can be configured with max_sync_workers_per_subscription parameter |
| DDL Replication Support | Yes (supports DDL replication using function pglogical.replicate_ddl_command) | No (DDL statements need to be triggered on the subscriber end manually) |
| Multi-Master Support | Yes (support for multi-master replication with built-in conflict resolution) | No (publisher-subscriber architecture only) |
| Conflict Resolution | Conflict resolution can be configured in different ways using pglogical.conflict_resolution parameter | No built-in conflict resolution (asynchronous) |
| Replication error handling | Replication goes down if conflict resolution is not sufficient to fix the error | Subscription can be set to disable if any replication error comes |
| Setup Complexity | Moderate to high (requires extension setup) | Simple to configure (part of core PostgreSQL) |
| Support Availability | V2 available as Open-source, V3 is merged with the PGD extension | Built into PostgreSQL support |
Why Migrate from pglogical to Native Logical Replication?
The transition from pglogical to native logical replication may be driven due to various factors:
- Simplified Maintenance: Native logical replication is built into PostgreSQL itself, so there is no need to maintain an external extension like pglogical.
- Performance and Reliability: Native logical replication has matured, providing better performance and stability for many use cases.
- Reduced Dependency: Native replication removes the dependency on third-party extensions and ensures compatibility with the core PostgreSQL features and tools.
- Long-Term Support: As PostgreSQL evolves, native logical replication will receive continuous improvements and bug fixes directly from the PostgreSQL project
- pglogical End of Support: The latest release of pglogical 3.7 extension has been merged with the Multimaster Postgres Distributed (PGD) project formerly known as BDR, which basically marks the extension as End of life, leaving only pglogical 2 available as an open-source solution.
Migration Strategy Overview
Before diving into the migration steps, it is essential to understand the key differences between pglogical and native logical replication.
Below is a diagram showing the outlook for the Migration strategy -
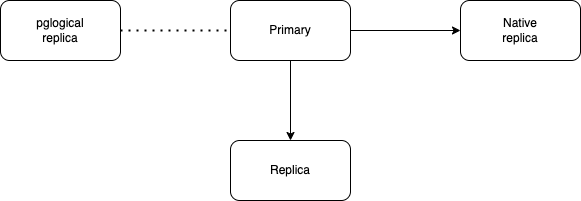
For Migrating a cluster using pglogical replication to Native logical replication, we will be using a 3 node cluster, with a Streaming Primary and Standby node and a Logical subscriber node replicating data from Primary node using pglogical replication. To Migrate the Logical node from using pglogical replication to a native logical replication node, we will spin up a fourth node, where we will setup the Native logical replication from Primary. This strategy will make sure the migration completes with minimal downtime on a live Postgres environment.
Migrating from pglogical to native logical replication involves the following key steps:
- Assess Current pglogical Setup
- Prepare PostgreSQL for Native Logical Replication
- Set Up Native Logical Replication
- Setup Subscription and start Data Migration
- Switch Application Traffic to New Replication Setup
- Post-Migration Cleanup and Verification
Now, let's go through these steps in detail -
Step 1: Assess Current pglogical Setup
Before starting the migration, it is essential to understand the existing pglogical replication setup. Below statements will list out the details of the objects getting replicated and the interface used in the pglogical replication -
SELECT * FROM pglogical.node;
SELECT * FROM pglogical.replication_set;
SELECT * FROM pglogical.replication_set_table;
SELECT * FROM pglogical.replication_set_seq;
Check for pglogical Subscription: Review the subscriptions in your current system:
SELECT * FROM pglogical.subscription;
SELECT * FROM pglogical.node_interface;
SELECT * FROM pglogical.show_subscription_status();The replication_set_table and replication_set_seq views show the list of objects getting replicated using pglogical replication. The node_interface view shows the connection string used by the Publisher node to replicate data and the show_subscription_status() function shows the current state of the pglogical replication.
Step 2: Prepare PostgreSQL for Native Logical Replication
Now that we have assessed the list of objects getting replicated, we will verify the replication roles and database parameters to make sure the PostgreSQL databases are correctly configured for the transition from pglogical to native logical replication.
Review the postgresql.conf file on both the primary and replica servers to make sure logical replication related parameters are configured and restart the databases if needed.
wal_level = logical
max_replication_slots = 12
max_wal_senders = 12
max_logical_replication_workers = 10
max_sync_workers_per_subscription = 4
wal_sender_timeout = 30min
wal_receiver_timeout = 30min
max_wal_size = 8GB
shared_preload_libraries = 'pglogical, pg_failover_slots'Adding 'pg_failover_slots' to shared_preload_libraries will help us setup High Availability on the Logical subscriber. This is discussed in detail later in the article.
Set Up Replication Roles:
Ensure the appropriate replication roles are created for your publisher and subscriber servers. On the primary (publisher), the replication user should have replication privileges:
CREATE ROLE replication_user WITH LOGIN REPLICATION PASSWORD 'password';Step 3: Set Up Native Logical Replication
Now, we can begin setting up Native logical replication on the new server. First, we will initialize the new Database cluster where Native logical replication will be configured. We will have a blank Postgresql cluster running on this server after initialization.
Restore Database / Table structure on the new server:
As Logical replication does not replicate DDL statements, first we need to restore the structure of the Database / Tables to be replicated using the Logical replication. We will use the pg_dump utility to migrate the database structure, we can also use pg_dumpall utility to migrate the DB Users and other global objects if needed.
These statements can be used to migrate the entire database structure and global objects to the Native subscriber node.
pg_dumpall -h publisher_host -g -f global_objects.sql
psql -f global_objects.sql > global_objects.out 2>&1
pg_dump -h publisher_host -U replication_user -d your_db -s -C -f db_structure.sql > your_db.sql
psql -f db_structure.sql > db_structure.out 2>&1NOTE: It is recommended to filter out Foreign key constraints from the Database / table structure dump and restore the foreign keys after Initial data sync is completed by the Logical replication. This will ensure all rows get migrated without causing errors due to Foreign keys on tables.
Create a Publication:
On the Primary (publisher) node, we will create a publication that defines which tables to replicate to the subscriber node. We will use the same list of tables getting replicated via pglogical replication here:
CREATE PUBLICATION my_publication;
SELECT 'ALTER PUBLICATION my_publication ADD TABLE '||set_reloid||';' from pglogical.replication_set_table;Or, if you want to publish all tables:
CREATE PUBLICATION my_publication FOR ALL TABLES;Step 4: Setup Subscription and start Data Migration
On the subscriber node, connect to the database where the Logical subscription needs to be created and create the subscription to pull data from the publisher:
CREATE SUBSCRIPTION my_subscription
CONNECTION 'host=publisher_host port=5432 dbname=your_db user=replication_user
password=your_password'
PUBLICATION my_publication;This command starts the replication process, and the subscriber will begin receiving changes from the publisher.
Monitor Replication:
To monitor the replication status for Native logical replication, you can check the status on the publisher node and subscription health on the subscriber node using below statements:
SELECT * FROM pg_stat_replication;
SELECT * FROM pg_stat_subscription;Native logical replication supports parallel data sync during the initial sync phase. Once the initial data sync is complete, logical replication will begin streaming changes to the subscriber node. On a live system, native logical replication will catch up with any changes made during the migration process.
NOTE: If you had filtered out the Foreign keys from the Structure dump during the Native logical setup phase, you can now restore those constraints as the Initial sync is complete.
Step 5: Switch Application Traffic to New Replication Setup
Once the replication is stable and synchronized, we will be synchronizing the Sequence last values on the subscriber node, to match the publisher node. This is done because the Logical replication does not update the Actual sequence values while migrating data, it only replicates the DML statements executed on the publisher side directly on the table.
We will use below script on the publisher node to generate the SQL statements to perform Sequence synchronization -
#!/bin/bash
port=5432
db=your_db
query="select schemaname as schema,
sequencename as sequence,
start_value,
last_value+100
from pg_sequences order by sequencename asc;"
while read schema sequence start_value last_value
do
if [ -z "$last_value" ]
then
echo "SELECT pg_catalog.SETVAL('${schema}.\"${sequence}\"', $start_value, true);"
else
echo "SELECT pg_catalog.SETVAL('${schema}.\"${sequence}\"', $last_value, true);"
fi
done <<< $(psql -t -A -F" " -p ${port} ${db} -c "${query}")This script will generate the SETVAL SQL statements for all Sequences on the database. We will execute these statements on the subscriber node to update the Sequence values there.
Lastly, we will verify the database logs for any issues / errors that could have come during the replication setup. If there is any error, it could probably be due to a DDL change on the publisher node, which was not propagated to the subscriber, as DDL replication is not supported in a Native Logical subscriber. If this happens, then we just have to manually trigger the same DDL statement on the subscriber node to fix the replication error.
Now, as the database is fully synchronized, we will switch the application / client connectivity to use the new Native Logical subscriber in place of the pglogical subscriber.
Step 6: Post-Migration Validation and Cleanup
After the migration, you should always perform Sanity checks on the subscriber node to ensure that the data on the publisher and subscriber are consistent. It can be done by comparing row counts or checksums for different tables to validate data integrity and consistency. If the validation is successful and everything looks good at your application, we can proceed with cleaning up the pglogical replication from the PostgreSQL clusters.
Drop Existing pglogical Replication Setup:
To prevent conflicts after the Application cutover, we will now stop the pglogical replication and remove all pglogical related dependencies from the Clusters.
On both the pglogical publisher and subscriber server, drop the replication set and nodes associated with pglogical:
SELECT pglogical.drop_replication_set('pglogical');
SELECT pglogical.drop_node('pglogical');On the publisher node, remove any existing pglogical replication slots:
SELECT pg_drop_replication_slot('pglogical_slot');Remove pglogical Extension:
If you are confident that the migration is complete and the system is stable, you can remove the pglogical extension from both the publisher and subscriber:
DROP EXTENSION pglogical;Backup the Database:
Finally, take a backup of the newly configured system to ensure we have a restore point after the migration.
One major difference between the pglogical replication and Native Logical replication configuration is that the support for DDL replication is not available with the Native Logical replication. You will have to explicitly configure how to run DDL statements on the Logical subscriber, so that Logical replication maintains its sync. This can be done by setting up Triggers that will keep track of the DDL statements and execute them on the Logical subscriber node.
Handling Replication Failover and High Availability
In any highly critical PostgreSQL environment, you want to ensure that if the primary node fails, a standby node can take over automatically. Tools like EFM, Patroni or repmgr can help automate the failover process providing High Availability and manage PostgreSQL nodes efficiently. Even though the streaming replication can handle a disaster by performing auto failover, if a Logical subscriber is connected to your old Primary node, the subscription will not work anymore as the primary node is no longer alive.
To handle such cases, newer versions of PostgreSQL have some built-in features, like from PostgreSQL v16 onwards, there is support for setting up a Logical publisher on a Streaming standby node. PostgreSQL v17 comes with added support for synchronization of Logical slots, by enabling the setting failover=true. This will keep the logical slots available and synchronized on both streaming primary and standby nodes. So during a failover, we can just update the connect string of the subscription to point it to the new primary to maintain the High Availability.
If you are running PostgreSQL on older versions, the pg_failover_slots extension adds the slot synchronization support, which also provides the functionality to make logical slots available on the Streaming replica nodes. Once you have installed the pg_failover_slots binaries for your PostgreSQL version and configured the database parameters, you will be able to see the Logical slots available under pg_replication_slots view in the Streaming standby node.
To configure your Logical standby node to be able to withstand a Failover, we will update the auto-failover function used by the Streaming replication utility and add below command to update the Connect string of the Subscription to point it to the new Primary node -
ALTER SUBSCRIPTION my_subscription CONNECTION 'new_primary_conninfo';With this update in place, whenever a Failover / Switchover happens on the PostgreSQL cluster, it will also update the subscription connect string to point it to the Current streaming primary node. This will make your Logical subscriber Highly available, extending High Availability to the whole PostgreSQL environment.
Conclusion
Migrating from pglogical replication to native logical replication in PostgreSQL offers numerous advantages, such as simplified configuration, better performance, and long-term support. By following the steps outlined in this article, you can successfully transition your Live database to native logical replication while ensuring minimal disruption to your PostgreSQL environment. Always test your configuration thoroughly and ensure data consistency before decommissioning the old replication setup.