PG Phriday: Defining High Availability in a Postgres World

What does High Availability actually mean when we’re discussing Postgres clusters? Sure, we can set an RPO, RTO, SLA, and other 3-letter acronyms regarding expectations and deliverables, but what are we trying to achieve? Fast failover? No lost transactions? Both? What about time necessary to rebuild or reclaim a former Primary node? How do all of our various replication configurables affect this?
Let’s see if we can come up with a definition of High Availability that’s suitable to a Postgres context. This may seem a trivial exercise at first, but there’s a method to our madness.
Starting from scratch
Let’s begin with a fairly general definition of High Availability before making it more Postgres-ey. Maybe something like this:
For the purpose of continuously providing database access, in the event the Primary writable Postgres node is unreachable, another suitable alternative may be substituted.
This is a good starting point because we don’t explain precisely how the node is substituted, nor when. In this case, the word “suitable” is also an extremely overloaded term. What makes a replacement node suitable?
I’m glad you asked!
Suddenly seeking suitability
What kind of criteria could we use in deciding whether any arbitrary node may replace a Primary under any circumstances? For example, let us presume we have a 3-node Postgres cluster that fits this design, containing three Postgres nodes distributed across three data centers, where node1 is the current Primary:
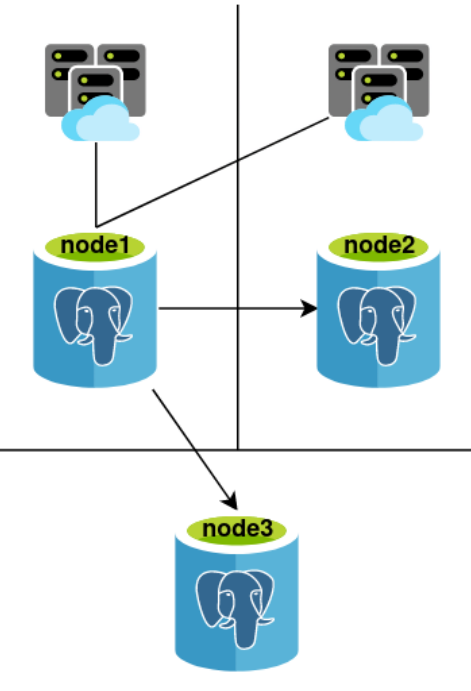
Excluding node1 as it is the current Primary, how do we select one of the remaining nodes as a replacement?
- Which of node2 or node3 are currently online and accepting connections?
- Are either (or both) of node2 or node3 using synchronous replication?
- Which of node2 or node3 have the lowest amount of replication lag?
- Do either node2 or node3 have a higher promotion priority?
Of these, the first criteria is generally the easiest to verify. Most Postgres HA systems will either maintain a connection to managed nodes or create new connections on detected events in order to determine cluster state. So assuming both of the remaining nodes are online, we move on to our next criteria.
Usually for Postgres clusters that require strong synchronization guarantees, we recommend using synchronous replication to ensure data written to the Primary is faithfully represented on at least one replica. Let’s assume for this cluster, the postgresql.conf file on node1 contains these two lines:
synchronous_commit = on
synchronous_standby_names = 'ANY 1 (node2, node3)'
Then, let’s assume node2 and node3 both name themselves properly by defining application_name in their primary_conninfo setting, like this:
primary_conninfo = 'host=node1 user=rep_user application_name=node2'
Note: Don’t forget that the primary_conninfo parameter was moved to reside directly in postgresql.conf in Postgres 12. Older versions will need to set this in recovery.conf instead.
So in this particular node arrangement, both node2 and node3 are synchronous replicas. However, this is only a three-node cluster, meaning it’s only really “safe” to require one of the replica nodes to acknowledge synchronous writes. That’s reflected in our example node1 configuration where we specify “ANY 1”. This means either node2 or node3 may acknowledge the transaction before allowing further activity in that session.
The implication here is that node2 could acknowledge a transaction before it reaches node3. In the event of a failover at that exact moment, we would expect node2 to have the least amount of transaction lag and therefore be the best promotion candidate. This is another key area where compatible HA systems must flex their familiarity with Postgres.
Such systems will regularly execute a query like this on all nodes:
SELECT pg_current_wal_lsn() AS current_lsn;
Lag is the amount of WAL data that has not yet reached an indicated node. Postgres HA systems maintain known WAL positions of all known cluster members, and in the event of a failover, elect the replica with the closest matching LSN. Given all of that, what happens when both nodes represent the same amount of transaction lag? This includes the (desired) instance where lag is zero.
Our last criteria is more of a preferential treatment. Many (if not most) HA systems allow ranking particular nodes by some kind of weight, all other things considered. In the event node2 had a weighted score of 50 and node3 was assigned 100, for example, node3 would be promoted.
A shifting definition
Is that enough to revise our High Availability definition slightly? Maybe something like this:
For the purpose of continuously providing database access, in the event the Primary writable Postgres node is unreachable, the highest-ranked online replica with the most recent LSN may be substituted. If synchronous replication is in use, the promoted node must have at least one synchronous write target.
The updated definition includes the concept of node ranking and the concept of WAL position. Note how we integrated synchronous nodes into the definition by mandating that synchronous design is maintained through a failover. This is important because the implication here is that synchronous Postgres clusters effectively require three nodes.
For other designs which only leverage asynchronous replication, our definition is still satisfied with two nodes. This is actually just fine, provided we don’t include failover automation. So long as a manual step is involved, the human being acts as the objective third party who is evaluating the state of the cluster before promoting a replica. This is the unnamed entity who is substituting our suitable candidate node.
Can we include automation in our definition? Of course!
Postgres isn’t a cluster
Such a bold statement probably deserves some explanation. At its heart, Postgres is a fully ACID database engine. As a consequence, it achieves the D in Durability by implementing a Write Ahead Log system it can leverage for crash recovery. In the old days, crash recovery required processing WAL files directly, and so all nodes were disconnected. When Postgres 9.0 introduced streaming replication, that merely provided a more efficient way to acquire WAL contents.
The relationship the Primary maintains with its replicas has slowly evolved over the years. The hot_standby_feedback parameter is one way the standby communicates with the upstream system. We also have the pg_stat_replication view to observe any downstream systems and their replication status. If slots are in use, there’s actually a persistent view of downstream replicas and their LSN positions in pg_replication_slots as well.
But a bidirectional channel and a bit of metadata here and there does not a cluster make. Replica nodes have no concept of any other existing replicas. If cascading replication is in use, the top node has no idea the cascaded nodes exist at all. Aside from clever overloading of the connection string, Postgres has no external routing system for contacting other cluster members. Postgres facilitates clustering of nodes to a certain extent, but by itself, is not a cluster. There are other database engines which operate as a fully orchestrated entity, but Postgres is not one of them.
A direct consequence of this, is that all Postgres High Availability tools attempt to step in to rectify this oversight. Some would suggest the best of these obfuscate the presence of Postgres nodes from client applications entirely. Regardless of how this is achieved, creating a cluster forces us to substantially revise our definition to something like this:
For the purpose of continuously providing database access, a quorum-backed cluster must present a writable Postgres endpoint. Should the current target become unusable, the cluster must identify and substitute the highest ranked online replica with the most recent LSN. If synchronous replication is in use, the promoted node must have at least one synchronous write target.
That’s quite a mouthful, but accomplishes quite a bit. First and foremost, the client just wants a Postgres endpoint, and doesn’t care how that occurs. Our quorum requirement ensures agreement among a majority of the cluster so we don’t have any accidents. That means the cluster must have at least three participating nodes, even if there are only two Postgres servers. The rest is largely the same as before.
A final revision
Given the above, a minimal cluster would look something like this:
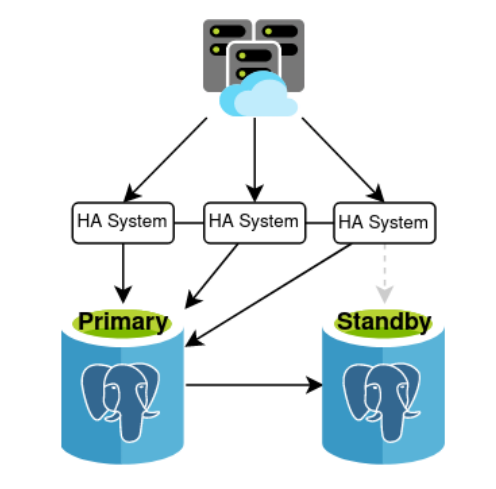
In this case, the “HA System” is acting as both the routing component and Postgres node manager as well. There are three participants for the sake of quorum, any HA node will redirect to the active Primary, and Postgres nodes are observed for status to determine next actions. It may not be the most elegant design, but it fills our requirements.
This is also a markedly different approach than some existing HA systems employ. While they make Witness, Monitor, or some other kind of impartial third node an optional component, few go so far as to require it. One of the few that integrates a third node into the actual design of the utility is pg_autofailover, with its definition of a Monitor entity. Patroni is another of these, in that it delegates quorum duties to a secondary dedicated layer, and that layer enforces its own node distribution and communication requirements.
Pg_autofailover was very clever in moving cluster monitoring to a dedicated service to ensure a Primary + Standby relationship couldn’t escape the presence of a third node. However, one could argue that the application layer still needs to know too much about our cluster, since every server DSN must be part of a multi-host connection string. Patroni goes one step further and translates the state of the cluster to HAProxy for connection routing purposes, and we end up with this:
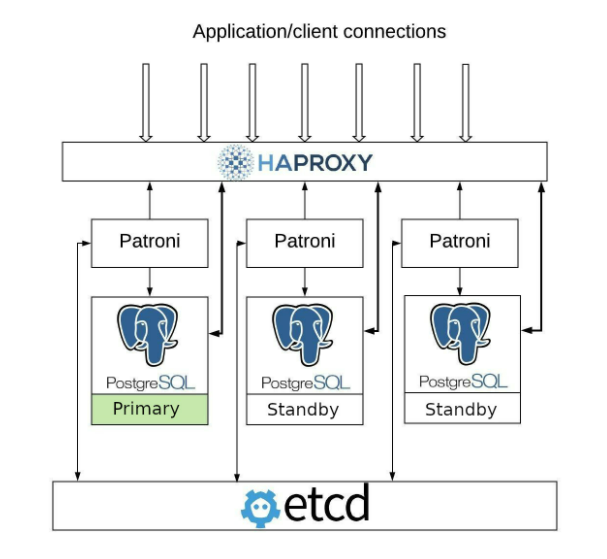
Thus both routing and quorum components are provided by external layers so Patroni can focus on Postgres node management. Why not a VIP or CNAME? How about reconfiguring PgBouncer instead? I covered this a bit in my Do’s and Don’ts of Postgres High Availability talk at Postgres Build, but these are all fundamentally flawed. They all function in a way that allows them to be defined for multiple Postgres nodes or may remain misconfigured if you can’t reach every node.
Back in 1999, I first encountered Oracle’s Listener service after asking the DBA how to connect to our Oracle systems. Out of curiosity, I examined the configuration file and despite the odd LISP-style syntax, it was clear that multiple nodes were listed, and I didn’t need to invoke any special incantations to reach the “right” one. Connect to the Listener, write to the resulting Oracle target. Done.
Patroni is great, but it relies too much on unreliable, difficult to configure, or fast-moving projects that don’t provide packages for common Linux distributions. HAProxy, for example, has a notoriously impenetrable manual that could double as a language definition codex. It’s also not purpose-built and needs to regularly poll each node for readiness as reflected by the Patoroni daemon. Why doesn’t Postgres have its own Listener equivalent? One that can connect to a quorum layer and immediately know the correct routing target? This would go a long way in making Postgres itself a cluster, rather than just a fragment of one.
To that end, let’s make one final revision to our definition of High-Availability with regard to Postgres:
For the purpose of continuously providing database access, a quorum-backed cluster must present a writable Postgres interface independent of cluster composition. Should the current target become unusable, the cluster must identify and substitute the highest ranked online replica with the most recent LSN. If synchronous replication is in use, the promoted node must have at least one synchronous write target.
By going the Listener approach—especially if the Listener is backed by a distributed consensus layer—the ultimate makeup of the Postgres nodes behind the interface is largely irrelevant. Thus instead of a single endpoint (or multi-host string) we simply provide a Listener that self-configures based on what it learns from the Consensus layer. We can add or remove nodes ad infinitum, and since they’re part of the new cluster architecture, the Proxy always has an accurate picture.
And that produces a corresponding alteration to our desired architecture as well:
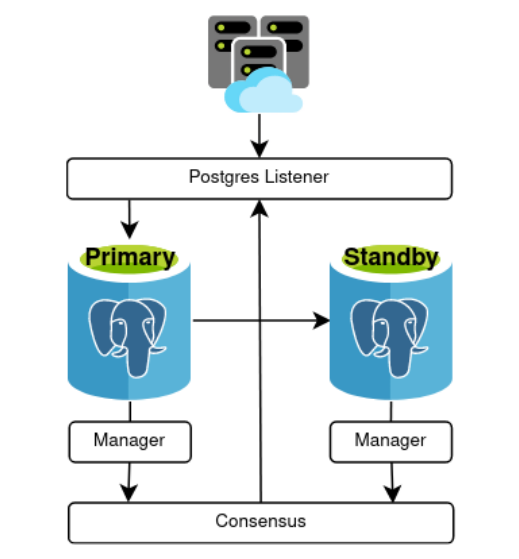
Seen this way, Postgres is still one minor portion of the cohesive whole. The Listener layer may consist of any amount of Listener services or nodes, and the Consensus layer is likely represented by 3-7 nodes on its own. This means the amount of extra work happening behind the scenes to maintain this relationship is nontrivial.
Future steps
As yet, there is no single Postgres HA solution that fits our (admittedly somewhat contrived) definition. Unlike Oracle or MongoDB for instance, Postgres is not a loosely connected constellation of associated services. There’s no “pg_consensus” or “pg_listener” daemon we can tap into for these essential features necessary for our imagined ideal HA system. If there were, we could dispense with etcd, consul.io, HAProxy, and their ilk, and treat Postgres as a true cluster rather than a loose collection of nodes.
There’s a longer conversation to be had here. For example, to do this properly, we would need to demote the “postmaster” daemon that acts as the core of Postgres. A higher level process would monitor the cluster consensus state and only start Postgres properly if this particular node wasn’t fenced or otherwise cut off from a quorum of nodes. And that’s only the beginning of what it would take to transform Postgres into a cluster with integrated High Availability.
Alas, that is a topic for another future PG Phriday.
Want to learn more about how to achieve extreme high availability for Postgres databases? Check out our eBook "EDB Postgres Distributed: The Next Generation of PostgreSQL High Availability!"