
A blog entry dedicated to leveraging pglogical to achieve bi-directional replication appeared on Amazon somewhat recently. Normally we would be elated to see users leveraging pglogical to solve everyday problems, but in this instance the topic filled us with a sense of dread. I personally felt a kind of creeping terror wrought from battle-tested experience; should this message spread, the High Availability Gods would be most irate.
Please, for all you hold dear, don’t do this. Do anything but this. While proprietary, BDR (Bi-directional Replication) is an extension that exists specifically to convey that functionality to Postgres safely. Doing this improperly can be actively destructive to your business, resulting in data loss, divergence, system outages, and more. We aim to explain just a few reasons why this is the case.
Hammer Time
We’ve all heard the adage: to a man with a hammer, everything looks like a nail. One of the cool features in pglogical is the conflict management functionality. Should a conflict occur, It allows incoming rows to either replace the existing row, be skipped in favor of existing data, or halt replication for manual intervention.
The pure intent of this feature is to facilitate Data Warehouse uses, where multiple regional nodes can all contribute to a single set of tables for analytical purposes. Combined with the fact that pglogical can skip the initial synchronization step, it’s always possible to add more regional data sources as they appear.
To a clever user, it also means you can build a bi-directional replication scheme. Simply create a typical logical replica, and then add a reciprocal relationship without copying the data again. It’s almost diabolical in its simplicity. Were the story to end there, we would even agree and advocate for this use case.
And yet, the best-laid plans of mice and men oft go astray.
Manual Intervention
The principal issue with using pglogical for bi-directional replication is not in building it, but keeping it built. It’s a foundation constructed on shifting sands rather than firm bedrock, with all that entails. Imagine everything starts out great, and we have this relationship for two tables:
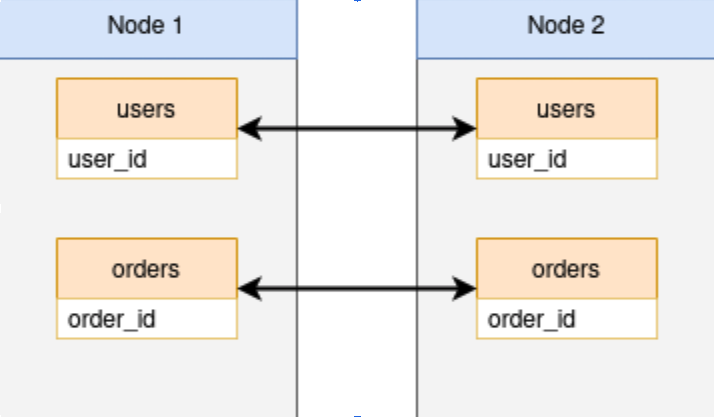
Consider what happens in the case of a node failure. Like native Postgres logical replication, pglogical relies on replication slots to track LSN position for all subscriber nodes. In the event a node is lost, so too are the slot positions. Losing the slot positions also renders the logical subscription as invalid. Should Node 1 fail, we might think we can reestablish the bidirectional relationship by performing these steps:
- Restore Node 1 from backup.
- Drop the subscription from Node 2 to Node 1, as the replication slots on Node 1 are gone.
- Recreate the subscription from Node 2 to Node 1, remembering to set the synchronize_data option to false.
- Wait for Node 1 to catch up to Node 2 since replication slots on Node 2 are fine.
The problem with this theory is that item 4 isn’t quite so straight-forward. When using Postgres logical replication, there are actually two tables on the receiving end that play a very critical role:
- pg_replication_origin - Stores information about the upstream origin node for logical replication data.
- pg_replication_origin_status - Tracks the local and remote LSN positions for an established logical replication slot.
An obscure attribute of replication slots is that these tables dictate the last known good position on the consuming node, so they will fast-forward to the first position it requests. If Node 1 is restored too early in the timeline, these tables are adjusted to match the first available location in the slot. This means we would need to restore Node 1 to at least the LSN where the failure occurred in order for steps 1-4 to be safe, or Node 1 would likely end up with missing data. That’s easier said than done in a failure scenario.
Given these limitations, most DBAs would offer up an alternative series of steps to re-establish the bi-directional replication relationship: rebuild it from scratch. This means re-synchronizing all of the tables in the publication, or potentially using some kind of data comparison and validation tool instead. Then comes reproducing the reciprocal subscription to make it bi-directional. And this must be done any time there is a node failure.
And it’s not just failures. Replication slots are not currently copied to physical streaming replicas, so if Node 1 had a copy named Node 1b, every node switchover would require this:
- Temporarily disable the subscription on Node 2 so it disconnects from Node 1.
- Recreate the replication slot required by Node 2 on Node 1b.
- Stop Node 1 for maintenance.
- Promote Node 1b.
- Enable the subscription on Node 2.
And when Node 1 comes back online, we would need to drop the slot Node 2 was using there to avoid retaining excessive WAL files on that system. This must happen for every node promotion without exception. Sure it can be scripted, but there’s a lot of room for failure here and all steps should be verified or the whole procedure needs to be scrapped. And then, of course, we’d have to rebuild the bi-directional relationship yet again.
Consider also that these issues compound linearly. If we also have Nodes 3 and 4 in the cluster, they also require the same treatment on a failover of Node 1. They also require the same potential for a rebuild any time there’s a problem that can’t be easily resolved.
And this is just the tip of the iceberg.
Did I Do That?
It’s a rare database indeed where no new tables, columns, indexes, or other such structures will ever be created in the future. Perhaps one of the most contentious issues with pglogical and native logical replication is that they don’t support DDL replication. Thus every single new column, table, index, trigger, and other schema modification, must be coordinated on all nodes or risk disrupting replication.
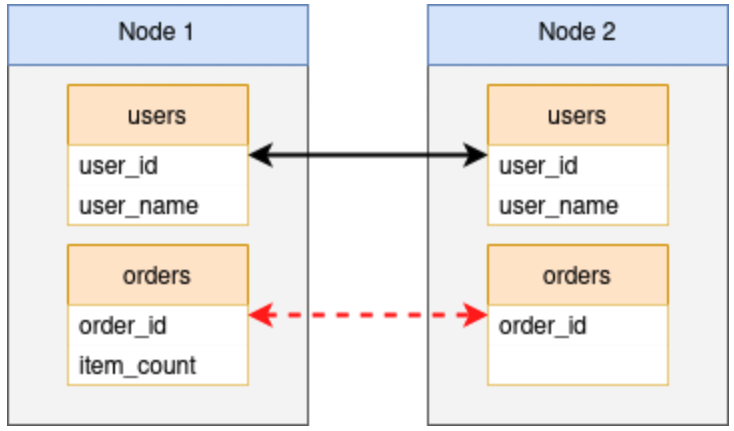
While pglogical provides a function named replicate_ddl_command() to overcome this particular shortcoming, it’s not a panacea. Use of this function must be either absolute or circumvented only in specific cases, with node-by-node migrations where short replication outages are acceptable. All other scenarios will break replication in a way that will only appear in the logs as somewhat esoteric complaints of missing or otherwise incompatible columns, and background worker exits.
Another problem here is one that’s somewhat more unintuitive: mixed transactions. Consider this basic transaction series being executed by replicate_ddl_command():
SELECT replicate_ddl_command($BODY$
ALTER TABLE foo ADD mycol TEXT NULL;
UPDATE foo SET mycol = othercol::TEXT;
ALTER TABLE foo ALTER mycol SET NOT NULL;
$BODY$);
This transaction doesn’t just modify the underlying table, it also updates the contents. What if another session dropped the othercol column right as this ran and also resolved first, or did so from another node entirely? Depending on when the changes are applied on each node, the ALTER may run, but the UPDATE won’t. The replicate_ddl_command() function works by manually adding the statements into the replication queue, so any nodes disrupted this way may need to have the subscription rebuilt, depending on how complex the transaction was.
Perhaps even more insidious are seemingly compatible DDL changes during a rolling node-by-node modification. Since pglogical is a live logical replication system, it may be tempting to do this:
ALTER TABLE foo DROP COLUMN oldcol;
This will drop the column on Node 1, and we can manually run it on Node 2 afterwards, right? Well… maybe. What if Node 2 accepted a write transaction before the DDL completed on Node 1? And then it transmitted a row containing the missing column to Node 1? Unaware of this, we run the DROP COLUMN on Node 2 as well, and it succeeds. Yet replication between Node 1 and Node 2 is broken in a way that will prevent Node 1 from replaying any statements from Node 2 in the future, because at least one incompatible statement containing oldcol is in the replication queue.
Meanwhile, Node 2 has data that’s not represented on Node 1. In some cases it’s possible to resolve errors like this by temporarily adding missing columns or DDL, but that’s not always the case. Oftentimes it must, once again, be manually resolved by rebuilding subscriptions between the two (or three, or four) affected nodes.
The Truth About Conflicts
Any bi-directional replication system must account for conflicts. Just because the word “conflict” appears in the pglogical documentation, does not make it appropriate for use in a bi-directional context. What does that mean?
These are the conflict types supported by pglogical:
- error - Replication will stop on an error if a conflict is detected, and manual action is needed for resolving.
- apply_remote - Always apply the change that's conflicting with local data.
- keep_local - Keep the local version of the data and ignore the conflicting change that is coming from the remote node.
- last_update_wins - The version of data with the newest commit timestamp will be kept (this can be either the local or remote version).
- first_update_wins - The version of data with the oldest commit timestamp will be kept (this can be either the local or remote version).
If system clocks are well synchronized and track_commit_timestamps is enabled, the safest on this list is usually last_update_wins. Clever combinations of keep_local and apply_remote on various subscriptions can accomplish certain kinds of retention preferences by node so a preferred node always wins disputes. But that’s the absolute pinnacle of conflict management pglogical can reach.
It turns out there is an entire Doctoral Thesis worth of unhandled conflict scenarios here, and pglogical is not suited to manage any of them. Let’s go over a few of the more obvious ones to have some idea about what’s missing.
Merge Conflicts
Consider this scenario on Node 1:
UPDATE account
SET balance = balance + 10000
WHERE account_id = 1511;
And this happens on Node 2 at almost exactly the same time:
UPDATE account
SET balance = balance + 25000
WHERE account_id = 1511;
The balance of this account will either increase by 10,000 or 25,000, but not both. But both bank branches processed the transaction and accepted the result, so what do we do? If we follow naive conflict management rules such as last_update_wins, we have a rather irate customer that’s lost a minimum of $10,000.
Unlike pglogical, BDR can resolve the conflicts discussed here in at least three different ways:
- Write a custom conflict management trigger on the “account” table which intercepts incoming data and properly merges it with existing content. This can be done to occur only during a conflict or for every incoming row, in case certain transformations must always occur for one reason or another.
- Use a Conflict-Free Replicated Data Type (CRDT) for the “balance” column to automatically merge data from different nodes and present it as a cumulative sum or delta.
- Using Eager Replication, which creates a prepared transaction on every node and quorum locking to ensure a majority of nodes agree on the effect of the UPDATE before it is applied. This particular solution essentially solves all conflict types directly, but due to consensus traffic, is also relatively slow and considered a last resort. Still, this option is not available to pglogical.
Column Level Conflicts
There’s a similar, but distinct variant to a merge conflict where modified data doesn’t overlap at all. Consider this:
UPDATE account
SET balance = balance + 10000
WHERE account_id = 1511;
And this happens on Node 2 at almost exactly the same time:
UPDATE account
SET locked = true
WHERE account_id = 1511;
Now our customer has either lost $10,000 or their account has been locked.
“But wait!” you might be saying, “Isn’t Postgres running each query on each node?”
It’s an understandable mistake, but the answer is decidedly “No.” What Postgres actually transfers in the logical data stream is the entire data tuple. So Node 1 sends (1511, 150000, false), while Node 2 transfers (1511, 140000, true), and never the two shall meet. This is because row contents are not truly “done” until they are written to disk in the WAL, because triggers, column defaults, or other effects may modify the contents. It’s the contents of the WAL that get transmitted, not the raw SQL statement.
Once again, relying entirely on pglogical for bi-directional replication has lost data in our cluster. On the other hand, BDR directly supports Column-Level Conflict Resolution so updates which modify different column sets are treated more like they were vertically partitioned. Thus both nodes eventually store a (1511, 150000, true) tuple, even though neither received such directly.
INSERT Conflicts
This one is more obvious, but still a valid concern. On Node 1, we receive this:
INSERT INTO customers (id, name)
VALUES (100, 'Bob Smith');
And on Node 2:
INSERT INTO customers (id, name)
VALUES (100, 'Jane Doe');
Now we’ve lost an entire customer, since the Primary Key produced a conflict, and we can keep only one of these rows. This can get even more confusing if the account creation process makes entries in several dependent tables over the course of a few minutes while data entry comes in. As a result, each node could have a mix of data meant for Jane or Bob depending on commit timestamps.
Not only is this a disaster for data integrity, we’ve also potentially leaked sensitive information to either Bob or Jane depending on when they last loaded their account view. This could be a GDPR violation, and probably falls afoul of several other fiduciary regulations and could result in a lawsuit.
This can be sidestepped by implementing application-driven IDs and having a very firm concept of tracking the underlying node to prevent cross-talk. It’s also possible to modify the underlying sequence increments to an offset, such that Node 1 generates values like 1, 11, 21, and so on, while Node 2 uses 2, 12, 22. But any time a node is replaced or added to the cluster, this means always modifying said sequences, and never forgetting one, including any new sequences that are added as time passes. Yet more problematic failure-prone workarounds.
BDR integrates two different sequence types inherently, both of which guarantee no collisions between any node in the cluster. Once a sequence is marked as one of these types, BDR manages values through batches acquired from the consensus layer, or by algorithmically generating values compatible with cluster use.
Right Tool for the Job
Conflicts are not merely an afterthought to consider for spurious hypothetical scenarios. They are a legitimate and critical detail that must be integrated into the entire application stack in an ideal situation. But at a minimum, the replication engine itself must handle or at least facilitate mitigating the fundamental issues bi-directional systems present.
While a very capable logical replication utility, pglogical simply wasn’t designed to handle replication in more than one direction. And in fact, certain scenarios may serve to actually amplify data loss scenarios. BDR on the other hand, was written specifically to address complex conflict situations, and that what EDB Postgres Distributed solves. This is the difference between function and intent.
We also can’t undersell that we’re only scratching the surface in this article. Unlike pglogical, EDB Postgres Distributed operates under the assumption that other writable nodes exist. Adding a node integrates it into the others automatically. Removing it does likewise. There is no ad-hoc piecemeal series of contortions we have to execute on every node to make sure subscriptions go each direction. If we have a seven node writable cluster and add a node, we simply have an eight node writable cluster.
Using pglogical to emulate bi-directional operation does not benefit from this convenience and is extremely brittle as a result. One mistake on any of the nodes in such a constellation can result in having to rebuild the entire thing. Improper conflict management support will eventually lead to data divergence, sometimes in ways that are difficult to detect until it’s too late.
EDB Postgres Distributed isn’t for everybody, and we completely understand that. It’s not a free product, so it may be tempting to try and achieve the same result using available resources. But as ancient mapmakers used to say regarding uncharted territory: Here Be Dragons. Constructing an ad-hoc bi-directional cluster using pglogical might work after a fashion, but it will do so unpredictably, and not without a certain hint of looming catastrophe.