PGVector as Embedding Store in PrivateGPT

EDB has a long history of open source contributions, and while we’re best known for our contributions to Postgres, that’s not the only project we contribute to. e.g
In this post TQ dives into a recent contribution to the popular AI stack PrivateGPT.
Starting with PrivateGPT
I am a software engineer in EDB, have around 6 years of experience with kubernetes, cloud and cloud service providers. Currently working on the platform construction for EDB postgres AI cloud.
Recently we were running a Proof of Technology: build one AI assistant bot against our internal/private design documents. There were two solutions considered, fine-tuning the LLM or RAG. We decide to use the RAG , as fine-tuning an LLM:
- Is time consuming and costly
- Is not flexible, each time we have new documents we would need to fine-tune the LLM again…
In addition these documents are considered “sensitive” from a security perspective, it was important to run the AI locally so as not share the data with third party services.
PrivateGPT is a popular project that allows you to ask questions about your documents using the power of Large Language Models in scenarios without internet connectivity (100% private, no data leaks!) and a mature project which provides RAG framework, UI and rest api to be leveraged.
At the beginning we kept all documents/vectors on local directory, this lead to problems:
- Suffering the risk of losing data and vector generation is not cheap
Store to Postgres
Postgres is the most popular sql database around the world, it has a solid and rich ecosystem. Part of what makes Postgres so popular is its extensions. One increasingly popular extension catering to AI/vector workloads is PGVector an extension which expands PG with abilities to store and query data as vectors for example via similarity search. My colleague Gulcin wrote a nice introduction to pgvector last year.
With postgres, we could keep all necessary data (documents, vectors, indexes) into a single, solid, data store.
EDB is further extending Postgres so that it can directly understand and process AI data (such as text documents and images) on object storage, automatically compute vector embeddings with LLMs and support similarity-based AI data retrieval. This will significantly streamline and accelerate further the creation of generative AI solutions with Postgres. Find more details here, where you can also register to get free access to the tech preview.
Adding support for PGVector in PrivateGPT
Unfortunately when we were running our proof of technology, PrivateGPT didn’t support PGVector as the embedding store. The PrivateGPT code base is python, and that’s a language I’m familiar with and use regularly so I investigated what adding PGVector support to the project would look like.
I’m glad to say that the PrivateGPT project welcomed my contribution , and now PGVector is a supported vector store for the project!
Documentation on how to use pgvector in PrivateGPT.
Prerequisites
- Postgres (pgvector supports postgres 11+)
- Pgvector extension installed
- PrivateGPT installed
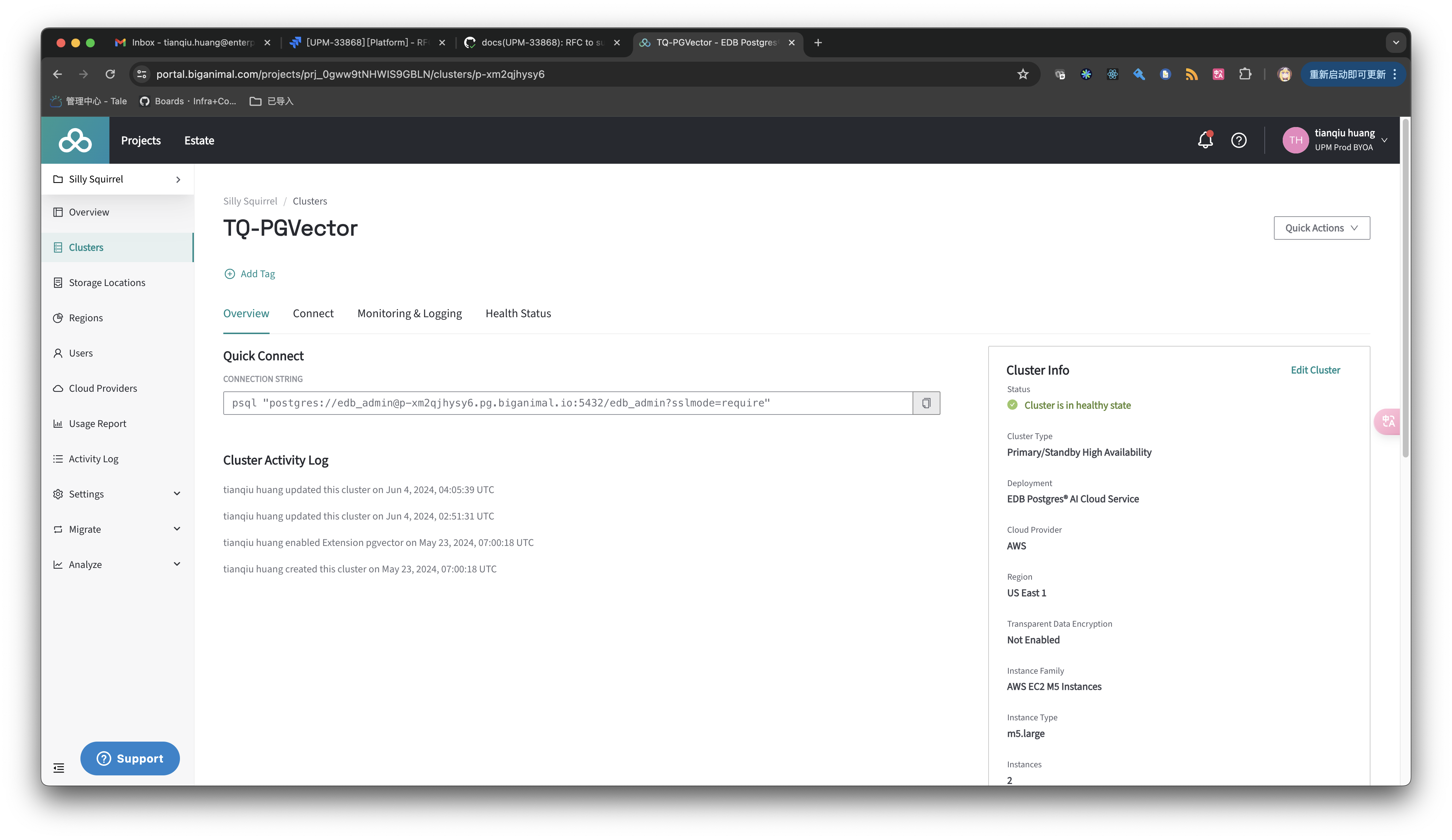
EDB Postgres AI Cloud Service provides a fully managed database with a bunch of extensions supported. During the Proof of Technology, we used one biganimal postgres cluster which had the pgvector extension installed.
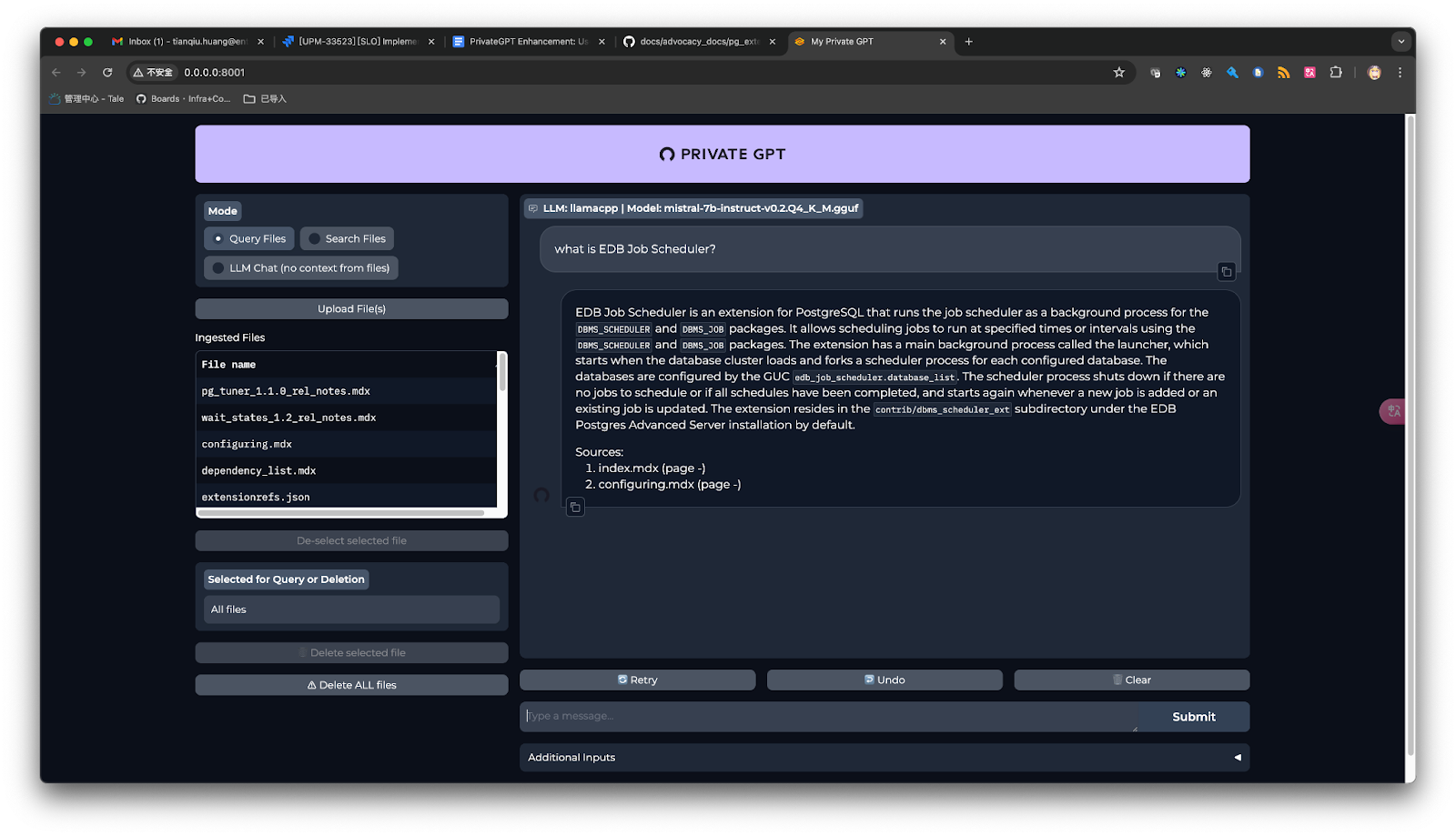
Interact with your documentations
1. Configure PrivateGPT to use pgvector as embedding store, under the folder to the PrivateGPT, apply the following changes to the settings.yaml
vectorstore: database: postgres postgres: host: p-xm2qjhysy6.pg.biganimal.io port: 5432 database: edb_admin user: edb_admin password: ${POSTGRES_PASSWORD:} schema_name: private_gpt2. Ingest knowledge base (documentations). I use edb public documentation https://github.com/EnterpriseDB/docs/tree/develop here.
$ poetry run python scripts/ingest_folder.py ~/go/src/github.com/enterprisedb/docs/advocacy_docs/pg_extensions3. Inside postgres, check the newly created table.
edb_admin=> \d private_gpt.* Table "private_gpt.data_embeddings" Column | Type | Collation | Nullable | Default -----------+-------------------+-----------+----------+--------------------------------------------------------- id | bigint | | not null | nextval('private_gpt.data_embeddings_id_seq'::regclass) text | character varying | | not null | metadata_ | json | | | node_id | character varying | | | embedding | vector(1024) | | | Indexes: "data_embeddings_pkey" PRIMARY KEY, btree (id) Sequence "private_gpt.data_embeddings_id_seq" Type | Start | Minimum | Maximum | Increment | Cycles? | Cache --------+-------+---------+---------------------+-----------+---------+------- bigint | 1 | 1 | 9223372036854775807 | 1 | no | 1 Owned by: private_gpt.data_embeddings.id Index "private_gpt.data_embeddings_pkey" Column | Type | Key? | Definition --------+--------+------+------------ id | bigint | yes | id primary key, btree, for table "private_gpt.data_embeddings"4. Start PrivateGPT and ask your questions
$ poetry run python -m private_gpt