Progress on online upgrade

In last couple of months I’ve been working on online upgrade for very large databases as part of the AXLE project and I would like to share my thoughts on the topic and what progress we have made recently.
Before joining 2ndQuadrant I used to work in Skype where the business would not allow a maintenance window for our databases. This meant no downtime was allowed for deployments, upgrades, etc. That kind of rule makes you change the way you do things. Most changes are small, you don’t do any heavy locks, you have replicas to allow for fast fail-over. But while you can make your releases small and non-blocking, what happens when you need to do a major version upgrade of the PostgreSQL database?
You might be in a different situation, as most companies do have an upgrade window, and so you might afford some downtime during the upgrade. This however brings two problems. For one, no company actually likes the downtimes even if they are allowed. And more importantly once your database grows beyond gigabytes in size into the range of terabytes or hundreds of terabytes, the downtime can take days or even weeks and nobody can afford to stop their operations for that long. The result is many companies often skip important upgrades, making the next one actually even more painful. And the developers are missing new features, performance improvements. They (the companies) sometime even risk running a PostgreSQL version that is no longer supported and has known data corruption or security problems. In the following paragraphs I will talk a little about my work on making the upgrades less time consuming and as result less painful and hopefully more frequent.
Let me start with a little history first. Before PostgreSQL 9.0 the only way to do a major version upgrade was to run pg_dump and restore the dump into an instance running a newer version of PostgreSQL. This method required the structure and all data to be read from the database and written into a file. Then read from the file and inserted into a new database, indexes have to be rebuilt, etc.
As you can imagine this process can take quite some time. Improvements in performance were made in 8.4 for pg_restore with the -j option added where you could specify how many parallel jobs to be run. This makes it possible to restore several tables (indexes, etc) in parallel making the restore process faster for custom format dumps. The 9.3 version added similar option to pg_dump, improving the performance even further. But given how fast data volumes are growing, the parallelization itself is not enough to make any serious gain in the time required for upgrade.
Then in PostgreSQL 9.0 a utility called pg_upgrade arrived. Pg_upgrade dumps just the structures and restores them into the new cluster. But it copies the data files as they are on disk which is much faster than dumping them into logical format and then reinserting. This is good enough for small databases because it means a downtime in range of minutes or hours, a time acceptable for many scenarios. There is also the link mode which just creates hard links (junction points on Windows) which makes this process even faster. But from my personal point of view it is too dangerous to run such setup on a production master server. I will briefly explain why. If something goes wrong, once you start your new server that was upgraded using the link mode, you are suddenly without production database and have to fail-over, or worse, you have to restore from backup. That means you not only failed to upgrade but you just caused additional downtime! Good luck getting approval next time.
Now many people who can’t afford long downtimes for upgrades use the trigger based replication solutions like Slony or Londiste to do the upgrade. This is a good solution because you can replicate your data while the original server is running and then switch with minimal downtime. In practice there are several problems however. One of them is that the trigger based solutions are often clunky to setup, especially if you are doing it only once every couple of years and only to do the upgrade. It is also easy to miss a table or to add tables in wrong order and thus not getting the full copy. I have witnessed this in practice and people doing the upgrade were working with the trigger based replication on daily basis. Another issue is that the trigger based solutions add considerable load on the source database, sometimes making the upgrade impossible due to the database server becoming overloaded once the replication is activated. And last but often not least, it can take very long time for the trigger based replication to actually move the data to the new server. On the last occasion I was involved with an upgrade project, the trigger based solution took around a month to copy the database and catch up with changes. Yes, one month.
With PostgreSQL 9.4 arrives the logical decoding feature which offers a fresh start for designing a new and better online upgrade problem solution. What we did, as part of AXLE project, is to create a tool which combines the logical decoding with the techniques described above. The solution solves most of the problems of previous approaches. The Uni-Directional Replication PostgreSQL extension (UDR for short) does logical replication using logical decoding of the write ahead log (WAL). Thanks to this, the impact on the master server is almost on par with the physical streaming replication, so the additional load caused by ongoing upgrade is minimal on the running system. Also it provides tools to initialize new nodes, both using physical and logical backup. You can even turn existing physical standby to UDR standby. And because it is a logical replication system, it is possible to design it in a way that supports cross-version replication.
What all this means is we can now use UDR in combination with pg_upgrade to do an online upgrade of major PostgreSQL version with minimal downtime, in short amount of absolute time and with minimal impact on the running system.
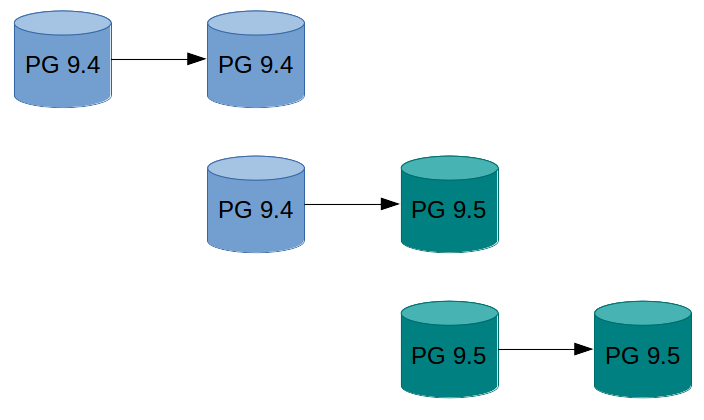 An example how this can look in practice:
An example how this can look in practice:
- Do pg_basebackup of existing instance.
- Setup the UDR replication between original instance and the one created by basebackup.
- Pg_upgrade the new instance.
- Let UDR replay the changes that happened in meantime.
- Switch the traffic to the new instance.
For howto with more detailed instructions see the UDR Online Upgrade guide on PostgreSQL wiki. The UDR sources are available in the 2ndquadrant_bdr repository on PostgreSQL git server (bdr-plugin/next branch).
Finally, since UDR is not just an online upgrade tool but also a replication solution, it can be used for your normal replication needs, instead of the physical streaming replication. Furthermore it provides several advantages like ability to create temporary tables, replicating from multiple OLTP databases into one big data warehouse database, or replicating just part of the database.
My hope is that this effort will mean that downtime considerations are no longer a problem when it comes to upgrading from PostgreSQL 9.4 and above to a new major version.
The research leading to these results has received funding from the European Union’s Seventh Framework Programme (FP7/2007-2013) under grant agreement n° 318633.