Scaling Breakthrough: EPAS 17 Scales Twice as Well, Thanks PostgreSQL!

Do you have a workload that requires extreme transactional performance, Oracle compatibility, or enhanced enterprise functionality?
EPAS 17 is the solution. Let’s find out why.
Thanks to the open-source community that maintains PostgreSQL, the release of EDB’s Postgres Advanced Server (EPAS) 17, and its advancements in scaling efficiency have set a new benchmark, nearly doubling the performance capabilities of its predecessor, EPAS 16.
How did PostgreSQL accomplish this feat? They added more magic elves. Well, no. Unless you consider code to be elves. Elves that have SHA-256 hashes as names…And live in a repository. I’m not sure which elf did the most, but I’m sure they all had a hand. Here are a few:
- Optimize WAL insertion lock acquisition and release
PostgreSQL 17 continues to improve the performance of its I/O layer. High concurrency workloads may see up to 2x better write throughput due to improvements in write-ahead log (WAL) processing. Additionally, the new streaming I/O interface speeds up sequential scans (reading all the data from a table) and how quickly ANALYZE can update planner statistics. - PostgreSQL 17 also extends its performance gains to query execution. PostgreSQL 17 improves the performance of queries with
IN clauses that use B-tree indexes, the default index method in PostgreSQL. - Allow the grouping of file system reads with the new system variable io_combine_limit
While these results show a significant improvement in EPAS, we can’t forget that these gains are only because of the progress made by the PostgreSQL community. Our Postgres forks– EPAS and EDB Postgres Extended Server (PGE), follow community PostgreSQL extremely closely, unlike some so-called PostgreSQL-compatible products. EDB directly contributes to community PostgreSQL via our patches, feature enhancements, code reviews, mentoring of new community members, and other community activities.
In addition to the improvements made in PostgreSQL, EPAS has added a few enhancements to assist with performance. As one example, EPAS 17 modifies partitioning to obtain locks after pruning, leading to much better performance when you have many partitions. Depending on your workload, this can be a considerable improvement.
How are we testing?
Transparency is a crucial element of any benchmark. You should be able to reproduce performance results claimed by any database. I’ve included everything you need to perform the same test I did, including the test methodology, environment setup, and configuration.
This article compares EPAS 16 and EPAS 17 performance using HammerDB, a TPC-C-like benchmark kit running an OLTP workload. You could use a different one, but HammerDB has become an industry standard. It is the leading benchmarking and load-testing software for the world’s most popular databases, supporting Oracle Database, Microsoft SQL Server, IBM Db2, MySQL, MariaDB, and PostgreSQL.
HammerDB is a fair-use implementation of the popular TPC-C and TPC-H benchmarks. It’s free and open-source software, with source code hosted by the TPC on GitHub and managed by the TPC-OSS subcommittee.
The test is designed to run HammerDB over a dataset that fits in memory to show the performance improvement of EPAS 17 compared to EPAS 16 without being affected by storage bottlenecks.
HammerDB performed transactions without any user delay, driving the maximum number of transactions. Real-world scenarios have user delay, but this approach lets us observe the system's performance under the most demanding workload. We captured a metric called New Orders Per Minute (NOPM) during benchmark testing to verify performance.
The NOPM metric can be used to compare different database engines.
I wanted to use a newer box with substantial hardware resources, so our friends at Supermicro, an EDB partner, helped us out.
| OS | RHEL 9.5 (5.14.0-503.14.1.el9_5.x86_64) |
| CPU | 2x Intel(R) XEON(R) GOLD 6538N (32c) |
| RAM | 1024 GB |
| Storage | 4x SSD U.2 NVME 7.68 TB PCIe v5 - RAID 10 Postgres data 2x SSD U.2 NVME 7.68 TB PCIe v5 - RAID 0 Postgres wal 1x SSD M.2 NVME 960 GB - Operating system |
Benchmark settings
Below, the code snippet contains HammerDB configuration for dataset build and workload run.
Build database schema:
#!/bin/tclsh
puts "SETTING CONFIGURATION"
dbset db pg
diset connection pg_host "localhost"
diset connection pg_port "5444"
diset tpcc pg_defaultdbase "postgres"
diset tpcc pg_count_ware 5000
diset tpcc pg_num_vu 128
diset tpcc pg_raiseerror true
diset tpcc pg_superuser "enterprisedb"
diset tpcc pg_superuserpass "123"
diset tpcc pg_user "tpcc"
diset tpcc pg_pass "tpcc"
diset tpcc pg_oracompat false
diset tpcc pg_storedprocs false
diset tpcc pg_partition true
buildschema
puts "BUILD COMPLETE"
Run benchmark:
#!/bin/tclsh
puts "SETTING CONFIGURATION"
dbset db pg
diset connection pg_host "localhost"
diset connection pg_port "5444"
diset tpcc pg_raiseerror true
diset tpcc pg_defaultdbase "postgres"
diset tpcc pg_superuser "enterprisedb"
diset tpcc pg_superuserpass ""
diset tpcc pg_user "tpcc"
diset tpcc pg_pass "tpcc"
diset tpcc pg_driver timed
diset tpcc pg_duration 10
diset tpcc pg_rampup 4
diset tpcc pg_timeprofile false
diset tpcc pg_allwarehouse true
diset tpcc pg_oracompat false
diset tpcc pg_storedprocs false
diset tpcc pg_vacuum true
puts "SEQUENCE STARTED"
foreach z { 1 4 8 16 32 64 96 128 192 256 320 } {
puts "VU TEST $z "
loadscript
vuset vu $z
vuset logtotemp 0
vucreate
vurun
vudestroy
}
puts "TEST SEQUENCE COMPLETE"
exit
Database parameters
Below are the parameters that have been changed from a default postgresql.conf configuration.
max_connections = 1000
shared_buffers = 256GB
effective_cache_size = 512GB
work_mem = 8MB
maintenance_work_mem = 64GB
effective_io_concurrency = 200
maintenance_io_concurrency = 200
max_worker_processes = 128
max_parallel_maintenance_workers = 64
checkpoint_timeout = 1d
max_wal_size = 2500GB
min_wal_size = 64GB
random_page_cost = 1.0
vacuum_cost_limit = 8000
autovacuum = off
autovacuum_freeze_max_age = 1000000000
autovacuum_multixact_freeze_max_age = 1000000000
max_locks_per_transaction = 512
edb_dynatune = 0
Results
Let’s aggregate the results of the tests into a chart:
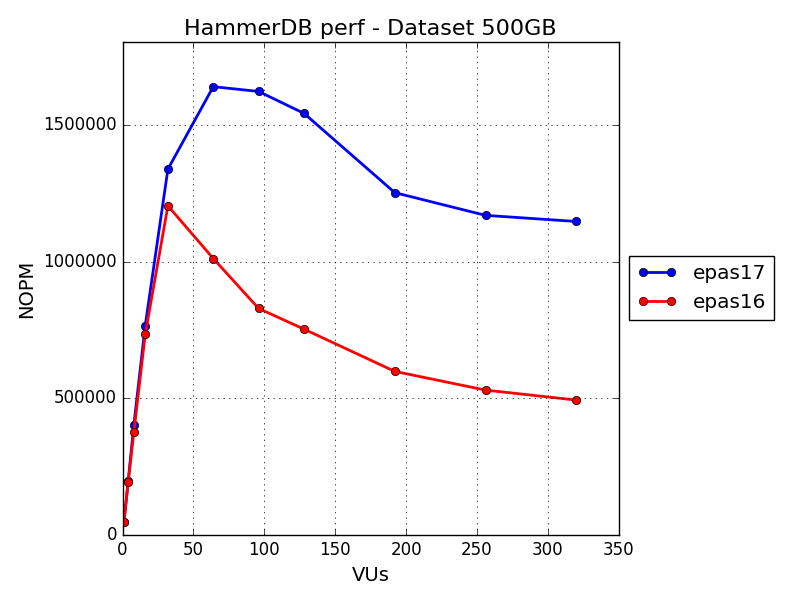
At first glance, we can see that the first virtual users (VUs) performance is similar. Still, at 32VUs, we begin to see the benefit that EPAS 17 brings, achieving 11.5% more performance, increasing at 62% at 64VUs and further increasing until its peak at 320VUs, with a stunning 132% performance gain compared to EPAS 16.
Because the test is meant to be cached, observing how the CPU utilization scaling differs from EPAS 17 and EPAS 16 without noise from the IO is worth observing.
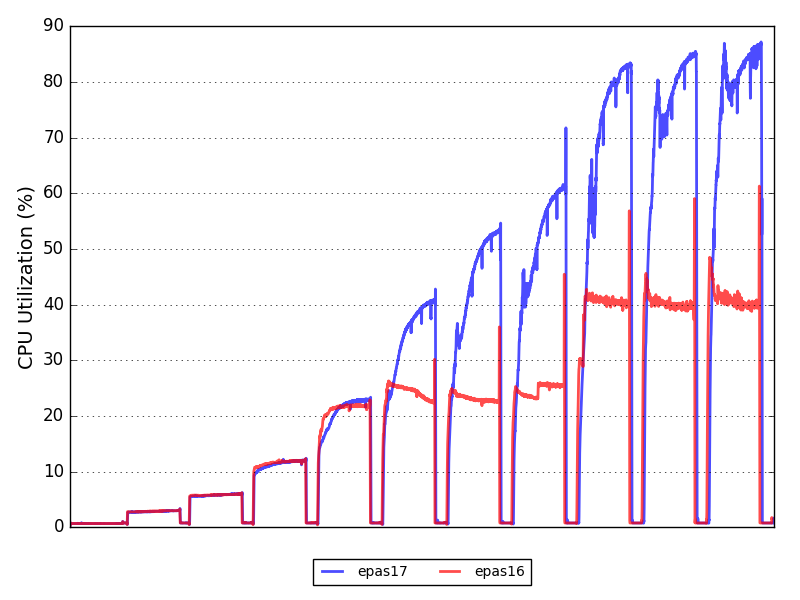
The chart above shows that EPAS17 uses CPUs more effectively, increasing scalability and bringing more than 100% gain at high concurrency levels.
Efficiently utilizing CPU throughput is essential for database engines, and EPAS17 has just made a significant leap forward.
Upgrading to a new PostgreSQL major version isn’t usually exciting, or at least not exciting in a good way. This time, though, there are some significant benefits. Just imagine the increased performance you can get from your existing hardware without capital expenditures. If that doesn’t make you rush to your local EDB package repository, I don’t know what will.
In summary, if you have a database and want to put some transactions in it, ensure you get some elves. They’re hard workers. Or, at least, that’s what they’ll tell you. Watch them. Carefully.