The Do's and Don'ts of Postgres High Availability Part 1: Great Expectations


There are some fundamental strategies inherent to deploying a functional and highly available Postgres cluster. We covered these in a 2021 webinar and wanted to make sure everyone had access to this critically important content. Now updated for 2023, we’ll cover our recommendations of what one should and shouldn’t do while building a HA Postgres cluster. In Part 1 of this series, we’ll provide tips on setting realistic expectations.
“Experience is simply the name we give our mistakes.”
– Oscar Wilde
High Availability is a varied and complex topic when it comes to databases like Postgres. The state of the art has changed considerably in just the last few years, and that alone can be quite daunting. But the fundamentals we rely on to make good architectural and tooling decisions are universal. They’re the experience the industry has collectively gathered since the beginning, the missteps and triumphs along the way.
We covered this topic back in December of 2021 as a Webinar and a follow-up Q&A, and we hope you find this slightly updated version useful in understanding HA in relation to Postgres.
Expectations
“As for the future, your task is not to foresee it, but to enable it.”
– Antoine de Saint-Exupéry
Most of these discussions start off with a bunch of acronyms. Maybe it’s RPO, RTO, SLA, or some other new buzzword. These are definitely important concepts, but it really comes down to expectations.
It’s not really possible to know how to build something unless you know how it’s supposed to operate. So our first Do: plan ahead! If we lay the foundation first, we can identify any possible tradeoffs and address known limitations before allocating a single server. How much RAM, CPU, and disk space should each instance get? How many instances? What other configuration may we wish to change? Make a list and ensure there’s an answer to every question.
RPO and RTO
Two of the things we need to define upfront are both the Recovery Point Objective (RPO) and Recovery Time Objective (RTO). There’s a business-driven definition of these terms, but it really comes down to this diagram:
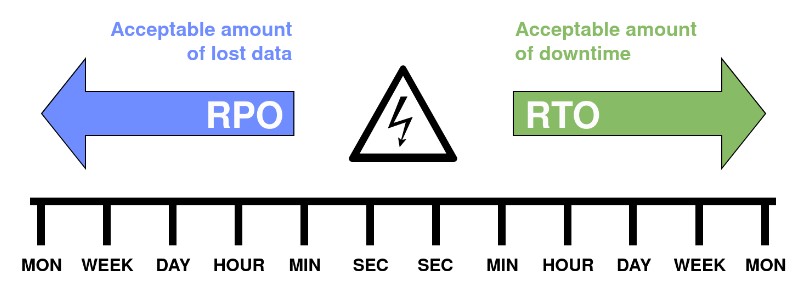
These two concepts go hand-in-hand, and the lowest amount of either tend to be the most expensive as well. We’ve all heard “Good, fast, cheap. Choose two,” before, and this is one of those decisions. And this becomes our second Do: define your exit conditions. How should our cluster operate in the face of adversity?
For its part, RPO will place inherent limits on acceptable technology. What is our recovery strategy? Should we switch to a replica or restore from backup? Should standby selection defer to the replica with least lag or closest proximity? Does the cost / benefit analysis support the extra replicas necessary for synchronous replication? What about backup scheduling and tools? All of these will affect our ultimate amount of data lost during a transition, and that’s only scratching the surface.
RTO can similarly influence design decisions. Downtime will affect our maintenance schedule. Can we afford a planned outage? What is the cumulative total of outages we will allow? How many “nines” of uptime do we want? How aggressive should the failover monitoring and timeouts be? Do we want to risk unnecessary failover events so they’re as fast as possible? Do we have to worry about split-brain, and what can we do to reduce that risk?
About PACELC
While we’re thinking about RPO and RTO, we come to our third Do: prioritize latency or consistency. Like the CAP theorem before it, PACELC forces us to make an exclusive decision. There’s no definitive way to pronounce PACELC, but we’ve long used pack-elk for the mnemonic value.

Who could forget this little guy?
Why does this matter when building a Postgres cluster? Because latency and consistency being exclusive will strongly influence what we end up building. Consider:
- Consistency requires agreement of node majority.
- This agreement takes time, and several round-trips.
- Thus Consistency (RPO) and Time (RTO) are mutually exclusive.
If we use synchronous replication to reduce RPO to its absolute minimum, we introduce write latency. Likewise, failover management systems must determine cluster state before failover if we want to reduce false positives, or have absolute consensus regarding replay status so we promote the most recent replica. This will necessarily increase our failover times. Know the tradeoffs before building anything, because it will determine how we build it.
Getting Low RPO with Postgres
Now that we know our definitions, what do we actually need to do to get low RPO with Postgres? Our next Do: consider n-safe synchronous. This is described at length in the Postgres replication documentation. To do it safely, we simply need to define this in our postgresql.conf file:
synchronous_commit = 'on'
synchronous_standby_names = 'ANY 2 (n1, n2, n3)'
This states our Primary node has three replicas, and only two must respond to the sync request, and allows us to perform maintenance on any single replica without affecting commit times. Using synchronous replication also means monitoring all replicas, because their status can ultimately affect the Primary node.
Backups can also benefit from streaming replication, bringing us to our next Do: stream WAL for backups. This is only possible by streaming WAL because WAL-shipping will only operate on full 16MB WAL files. Of all backup tools currently available for Postgres, only Barman will stream WAL files similarly to a Postgres replica. It’s even compatible with synchronous replication. We only need to make a couple of quick modifications to the barman.conf file:
streaming_archiver = on
streaming_conninfo = host=p1 … application_name=n1
The first change is necessary for streaming WAL archival, and the second defines the upstream server where Barman should connect for replication. Like with standby systems, we need to set the application_name if we desire to use synchronous replication.
Getting Low RTO with Postgres
Getting a fast failover with Postgres also means the old Primary will eventually need to be reintroduced to the cluster. Any time a node is down, our cluster is operating in a kind of degraded state we need to swiftly rectify or subsequent failovers may not be so speedy. That brings us to the next Do: be kind and rewind.
This can be accomplished with the pg_rewind utility. This command allows us to sync with another node much faster than a full sync with filesystem tools or pg_basebackup. It does have a few prerequisites for operation, however. The rewound server must be stopped, full page writes must be enabled, and data checksums or WAL hints must also be enabled.
The easiest way to do this to an existing server is with these two settings in postgresql.conf:
wal_log_hints = true
full_page_writes = on
Enabling checksums is much more difficult, since it requires either recreating the server at initialization time, or running a conversion tool across every file in the Postgres instance. New cluster can benefit from this by enabling the checksum flag:
initdb --data-checksums ...
And existing clusters may be converted if they’re Postgres version 12 or higher with this command while the cluster is stopped:
Can convert to checksums in 12+
pg_checksums --enable ...
And lastly in this category, we introduce our last Do: use replication slots. The goal here is to prevent replicas from falling behind. If they do incur lag or fall behind in replication, we want to let them catch up. And if they don’t or can’t for some reason, we want the primary node to limit any damage they might cause by doing so.
The easiest way to do this is to enable the following postgresql.conf parameter on replicas:
primary_slot_name = node1_slot
And the primary should always have this parameter set to limit WAL retention:
max_slot_wal_keep_size = 100GB
We used 100GB as an absolute maximum, at which point a slot will be marked as invalid. Replicas with invalid slots will need to catch up some other way, such as pulling from a WAL backup location, and the slot will need to be recreated.
Slots are also a central concept for Postgres logical replication, which transmits table data rather than binary WAL storage blocks. So if possible, embrace our next Do: integrate logical replication features. The reason this reduces RTO is that there’s no promotion needed, as logical replicas are always write-capable, and we can simply switch write targets. Since it’s the logical data rather than physical blocks, this means it’s also possible to perform Postgres major-version upgrades while fully online.
The main drawback to using native logical replication is that it’s more difficult to set up, requiring a publication / subscription model with strict handling of included tables and DDL synchronization. It’s also not bi-directional, making switching back much more difficult. Slots are also not natively retained during a failover event. EDB introduced the PG Failover Slots extension to address this specific item, but there are still several edge cases where it’s necessary to sync all data to a logical replica before it can resume logical replication.
And that brings us to the last RTO related advice, Don’t: fear EDB Postgres Distributed (PGD). It carries all the strengths of native logical replication, but is also bi-directional, keeps DDL in sync on all nodes, doesn’t lose slot locations during failover, and offers conflict management in case of write conflicts between nodes. Switching from one node to another is usually as simple as reconnecting, which is usually the ultimate in low RTO.
Stay tuned for Part 2 to dive deeper!
Want to learn more about maintaining extreme high availability? Download the white paper, EDB Postgres Distributed: The Next Generation of Postgres High Availability, to learn about EDB's solution that provides unparalleled protection from infrastructure issues, combined with near zero-downtime maintenance and management capabilities.