pgBouncer Setup, Extended Architecture, Use-cases and leveraging SO_REUSEPORT

April 26, 2021
A caveat: Peter Eisentraut (formerly of 2nd Quadrant, now an EDB company) and myself are both now EDB employees.
On August 13th, 2020 Peter Eisentraut blogged on the topic of spinning up multiple instances of pgBouncer listening on the same port to scale pgBouncer across more than one thread on a multi-threaded machine.
Peter’s blog remains the one-stop shop for leveraging the SO_REUSEPORT capabilities of pgBouncer using systemd in an efficient and graceful way.
However, there are some edge cases where this process requires a full recompilation of pgBouncer, or a slightly more complex workaround, where pgBouncer is not by default compiled to work with systemd. Also, we will discuss increasing the available TLS level of pgBouncer, an important security consideration.
In addition, I will demonstrate how to leverage all of this to supply load balanced traffic, including routing read and write statements to a master and multiple standbys, using multiple pgBouncer instances and the SO_REUSEPORT option.
So, let’s begin.
How to Install pgBouncer from Source
Here are some settings on an example installation from the PGDG repositories.
[phil@localhost ~]$ pgbouncer -V
PgBouncer 1.14.0
libevent 2.0.21-stable
adns: libc-2.17
tls: OpenSSL 1.0.2k-fips 26 Jan 2017
Looks good? But, there are two catches.
First, the OpenSSL version is 1.0.2k-fips, which only provides TLS support up to v1.2 and contains a number of security vulnerabilities.
Second, the pgbouncer installation hasn’t been precompiled by PGDG with --with-systemd, if it had been we would see something like this:
[phil@pgbouncer ~]$ pgbouncer -V
PgBouncer 1.15.0
libevent 2.1.8-stable
adns: evdns2
tls: OpenSSL 1.1.1d 10 Sep 2019
systemd: yes
Without that “systemd: yes” flag, we won’t be able to follow Peter Eisentraut’s cookbook for a simple and elegant scaling solution. In addition, in this version OpenSSL v1.1.1d includes support for TLS v1.3 (itself a bottom-up redesign of the entire secure network communication protocol).
At this point we have 2 options:
- Compile pgBouncer with systemd support using the --with-systemd flag, and fix the OpenSSL version along with it.
- Use multiple systemd scripts and ini files as a workaround, and live with the version of OpenSSL we have.
How to install pgBouncer with a full compilation from Source
Compiling from source isn’t for everybody. It’s complicated and easy to get wrong. You don’t get automatic updates and if it’s used in a corporate environment it could get you in a lot of regulatory trouble in terms of what are approved versions, and what aren’t approved.
That being said, it is a good option if you use isolated (or “air-gapped”) machines that can’t connect to the internet, and may also have limited or near-zero connectivity to other machines inside your network. Because once you have built it once, it’s relatively easy to build it again, as long as you can get what you need on to your target machine one way or another.
Before you begin compiling pgBouncer from source, then, you need to install some dependencies, among them the OpenSSL package. I’m running on Debian 10 from here on in (as CentOS 8 and on are no longer a great idea for production systems) and in the Debian 10 standard repositories OpenSSL is already at v.1.1.1d, which gives us the option to use TLS v1.3, as shown here:
phil@pgbouncer:~$ apt info openssl
Package: openssl
Version: 1.1.1d-0+deb10u5
Priority: optional
Section: utils
Maintainer: Debian OpenSSL Team <pkg-openssl-devel@lists.alioth.debian.org>
If you also need to install OpenSSL from source using GIT you can do so using the instructions on the OpenSSL Github page.
You can also build pgBouncer from source using GIT following the instructions on the building from git page.
If you don’t want to install git just for this or don’t have access to the internet, you can download the source tarball from the pgbouncer.org downloads page, transfer it to the target machine and untar it, or if you have curl and an internet connection you can grab the tarball file direct as shown below.
phil@pgbouncer:~$ sudo apt install libevent-dev libsystemd-dev libssl-dev libc-ares-dev pkg-config libc-ares2 curl
phil@pgbouncer:~$ curl -o pgbouncer-1.15.0.tar.gz https://www.pgbouncer.org/downloads/files/1.15.0/pgbouncer-1.15.0.tar.gz
phil@pgbouncer:~$ tar xf pgbouncer-1.15.0.tar.gz
phil@pgbouncer:~$ cd pgbouncer-1.15.0/
phil@pgbouncer:~/pgbouncer-1.15.0$ ./configure --prefix=/usr/local --with-systemd --with-cares
[..a lot of checks..]
Results:
adns = c-ares
pam = no
systemd = yes
tls = yes
And at this point we are ready to start the build.
A few points to note at this stage:
- As mentioned before, you don’t have to install curl, or download the file directly. If you have an air-gapped server (with no internet connection) you can download the tarball anywhere and transfer it onto the target machine as best you can. If so, omit the curl install and the curl call entirely.
- Use of the c-ares DNS name resolution package is optional. Earlier versions (below 1.10) are buggy with IPv6 addresses, however more recent (and less buggy) versions of c-ares have additional capabilities compared to the default libevent 2.x evdns component, which you may want to bake in as part of the build. If c-ares is available, pgBouncer will include it in the build by default. In the example above I have installed it using libc-ares2 and the development headers package libc-ares-dev, and forced it with the --with-cares flag, and it shows up in the Results summary as “adns = c-ares”.
- You may want to build with PAM (pluggable authentication module) support. In this case you will need to install the appropriate PAM libraries and use the --with-pam flag to include them and allow the “pam” authentication type in pgBouncer.
From here you can run “make” and “sudo make install” to complete the build from source.
phil@pgbouncer:~/pgbouncer-1.15.0$ make
[..verbose output..]
CCLD pgbouncer
phil@pgbouncer:~/pgbouncer-1.15.0$ sudo make install
INSTALL pgbouncer /usr/local/bin
INSTALL README.md /usr/local/share/doc/pgbouncer
INSTALL NEWS.md /usr/local/share/doc/pgbouncer
INSTALL etc/pgbouncer.ini /usr/local/share/doc/pgbouncer
INSTALL etc/userlist.txt /usr/local/share/doc/pgbouncer
INSTALL doc/pgbouncer.1 /usr/local/share/man/man1
INSTALL doc/pgbouncer.5 /usr/local/share/man/man5
And now if you check the -V flag of pgBouncer, you get:
phil@pgbouncer:~$ which pgbouncer
/usr/local/bin/pgbouncer
phil@pgbouncer:~$ pgbouncer -V
PgBouncer 1.15.0
libevent 2.1.8-stable
adns: c-ares 1.14.0
tls: OpenSSL 1.1.1d 10 Sep 2019
systemd: yes
Congratulations! You are now ready to follow Peter Eisentraut’s instructions on setting up pgBouncer in a scalable, secure (and elegant) way.
Cases where pgBouncer cannot be compiled from source and what to do
Perfectly reasonable. There are many advantages to installing from a repository, even if the software is out of date. At some point it will (or should) become up to date. Or maybe you have internal company repositories of trusted, tested software and you can only use those resources. In these cases installing from source is untrusted, untested and potentially unsafe, and there are no automatic updates to a build from source.
The only caveats to using pgBouncer with SO_REUSEPORT are that:
- The server kernel version supports it (i.e has SO_REUSEPORT support in the kernel)
- Note: that this was added in the Linux kernel version 3.9, so if you get:
$ uname -r 3.9.something...or higher - You should be good to go!
- Note: that this was added in the Linux kernel version 3.9, so if you get:
- The version of pgBouncer is v1.12 or higher. SO_REUSEPORT support was added in v1.12 of pgBouncer, so a lower version isn’t going to even give you the option of using it.
We’ll now run through the steps where systemd support isn’t available, but you still need to leverage SO_REUSEPORT.
Installing pgBouncer from PGDG gives me
root@pgbouncer:~# pgbouncer -V
PgBouncer 1.15.0
libevent 2.1.8-stable
adns: c-ares 1.14.0
tls: OpenSSL 1.1.1d 10 Sep 2019
So, no systemd support, even on Debian Buster and using the PGDG repositories.
Then I create some pgBouncer configuration files.
root@pgbouncer:~# cat /etc/pgbouncer/bouncer1.ini
;; bouncer1
;; Includes the default pgbouncer.ini file
%include /etc/pgbouncer/pgbouncer.ini
;; Overrides
[databases]
pgbench = dbname=pgbench host=127.0.0.1 user=pgbench password=foo
[users]
bounce = pool_mode=transaction max_user_connections=25
[pgbouncer]
listen_addr = *
logfile = /var/log/postgresql/bouncer1.log
pidfile = /var/run/postgresql/bouncer1.pid
auth_type = trust
so_reuseport = 1
unix_socket_dir = /var/run/postgresql/bouncer1_sock
root@pgbouncer:~# cat /etc/pgbouncer/bouncer2.ini
;; bouncer2
;; Includes the default pgbouncer.ini file
%include /etc/pgbouncer/pgbouncer.ini
;; Overrides
[databases]
pgbench = dbname=pgbench host=127.0.0.1 user=pgbench password=foo
[users]
bounce = pool_mode=transaction max_user_connections=25
[pgbouncer]
listen_addr = *
logfile = /var/log/postgresql/bouncer2.log
pidfile = /var/run/postgresql/bouncer2.pid
auth_type = trust
so_reuseport = 1
unix_socket_dir = /var/run/postgresql/bouncer2_sock
Both files include the /etc/pgbouncer/pgbouncer.ini file from the default install template, which is completely unchanged. All we have done is add two new files with the parameters we want. You can use any template you like and keep these files as minimal as you want.
Remember to set the listen_addr = '*' or pgBouncer will only listen on the sockets.
You’ll notice that the only difference between the two ini files is the log file, the pid file and the socket directory. You’ll need to create those socket directories manually as postgres.
postgres@pgbouncer:~$ mkdir /var/run/postgresql/bouncer1_sock
postgres@pgbouncer:~$ mkdir /var/run/postgresql/bouncer2_sock
Now we’ll complete the same kind of process with the systemd unit scripts.
root@pgbouncer:~# cat /etc/systemd/system/bouncer1.service
[Unit]
Description=pgBouncer connection pooling for PostgreSQL: Instance 1
After=postgresql.service
[Service]
Type=forking
User=postgres
Group=postgres
ExecStart=/usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini
ExecReload=/bin/kill -SIGHUP $MAINPID
PIDFile=/var/run/postgresql/bouncer1.pid
[Install]
WantedBy=multi-user.target
root@pgbouncer:~# cat /etc/systemd/system/bouncer2.service
[Unit]
Description=pgBouncer connection pooling for PostgreSQL: Instance 2
After=postgresql.service
[Service]
Type=forking
User=postgres
Group=postgres
ExecStart=/usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini
ExecReload=/bin/kill -SIGHUP $MAINPID
PIDFile=/var/run/postgresql/bouncer2.pid
[Install]
WantedBy=multi-user.target
Just make sure that your pid file locations are the same in both the ini files and the unit scripts, reload the systemd daemon and we’re ready to give it a try.
root@pgbouncer:~# systemctl daemon-reload
root@pgbouncer:~# systemctl start bouncer1
root@pgbouncer:~# systemctl status bouncer1
● bouncer1.service - pgBouncer connection pooling for PostgreSQL: Instance 1
Loaded: loaded (/etc/systemd/system/bouncer1.service; disabled; vendor preset: enabled)
Active: active (running) since Tue 2021-03-16 10:30:29 CET; 6s ago
Process: 27322 ExecStart=/usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini (code=exited, status=0/SUCCESS)
Main PID: 27324 (pgbouncer)
Tasks: 2 (limit: 2318)
Memory: 1.2M
CGroup: /system.slice/bouncer1.service
└─27324 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini
Mar 16 10:30:29 pgbouncer systemd[1]: Starting pgBouncer connection pooling for PostgreSQL: Instance 1...
Mar 16 10:30:29 pgbouncer systemd[1]: bouncer1.service: Can't open PID file /run/postgresql/bouncer1.pid (yet?) after start: No such file or directory
Mar 16 10:30:29 pgbouncer systemd[1]: Started pgBouncer connection pooling for PostgreSQL: Instance 1.
root@pgbouncer:~# systemctl start bouncer2
root@pgbouncer:~# systemctl status bouncer2
● bouncer2.service - pgBouncer connection pooling for PostgreSQL: Instance 2
Loaded: loaded (/etc/systemd/system/bouncer2.service; disabled; vendor preset: enabled)
Active: active (running) since Tue 2021-03-16 10:30:41 CET; 5s ago
Process: 27330 ExecStart=/usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini (code=exited, status=0/SUCCESS)
Main PID: 27332 (pgbouncer)
Tasks: 2 (limit: 2318)
Memory: 1.2M
CGroup: /system.slice/bouncer2.service
└─27332 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini
Mar 16 10:30:41 pgbouncer systemd[1]: Starting pgBouncer connection pooling for PostgreSQL: Instance 2...
Mar 16 10:30:41 pgbouncer systemd[1]: bouncer2.service: Can't open PID file /run/postgresql/bouncer2.pid (yet?) after start: No such file or directory
Mar 16 10:30:41 pgbouncer systemd[1]: Started pgBouncer connection pooling for PostgreSQL: Instance 2.
You’ll notice a warning that “Can't open PID file /run/postgresql/bouncer*.pid (yet?) after start: No such file or directory”, this is normal, the systemd daemon is just waiting for the pid file to be spun up by the pgBouncer daemonising call.
Eventually, we have both Instance #1 and Instance #2 up and running.
Now, let’s see if we can connect to the pgbench database defined in our .ini files. First we’ll create some tables and data with pgbench, and then connect to the pgbench database to look at them.
root@pgbouncer:~# /usr/bin/pgbench -h localhost -p 6432 -U bounce -i pgbench
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 100000 tuples (100%) done (elapsed 0.04 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done.
root@pgbouncer:~# psql -h localhost -p 6432 -U bounce pgbench
psql (11.10 (Debian 11.10-0+deb10u1))
Type "help" for help.
pgbench=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+---------
public | pgbench_accounts | table | pgbench
public | pgbench_branches | table | pgbench
public | pgbench_history | table | pgbench
public | pgbench_tellers | table | pgbench
(4 rows)
Which works! (Note also that I am connecting as the pgBouncer “bounce” user, which silently connects me to the “pgbench” user in the “pgbench” database).
But what happens when we put load on port 6432, where both of these instances should now be listening? Can we see the load being spread across the pgBouncer instances?
At rest, htop shows no real activity on pgbouncer:
CPU[| 0.7%] Tasks: 92, 126 thr; 1 running
Mem[||||||||||||||||||||||||||||||||||||||||579M/1.92G] Load average: 0.28 1.14 0.69
Swp[| 7.29M/975M] Uptime: 03:00:23
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
27524 postgres 20 0 19944 3304 2368 S 0.0 0.2 0:00.00 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini
27523 postgres 20 0 19944 3304 2368 S 0.0 0.2 0:39.43 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini
27542 postgres 20 0 19944 3456 2536 S 0.0 0.2 0:00.00 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini
27541 postgres 20 0 19944 3456 2536 S 0.0 0.2 0:13.99 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini
But when we run pgbench with 4 clients for a while, activity goes up smoothly.
root@pgbouncer:~# /usr/bin/pgbench -h localhost -p 6432 -U bounce -c 4 -T 300 pgbench
And checking in on htop, load is being spread evenly between bouncer1 and bouncer2:
CPU[|||||||||||||||||||||||||||||||||||||||||||||97.7%] Tasks: 93, 124 thr; 1 running
Mem[||||||||||||||||||||||||||||||||||||||||579M/1.92G] Load average: 0.52 0.68 0.58
Swp[| 7.29M/975M] Uptime: 03:03:44
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
27541 postgres 20 0 19944 3456 2536 S 10.9 0.2 0:15.24 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini
27523 postgres 20 0 19944 3304 2368 S 10.2 0.2 0:40.67 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini
27524 postgres 20 0 19944 3304 2368 S 0.0 0.2 0:00.00 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer1.ini
27542 postgres 20 0 19944 3456 2536 S 0.0 0.2 0:00.00 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer2.ini
So you even get a form of load balancing for free!
A shout out to edb-pgbouncer at this point, by the way, where all of this is taken care of for you.
In my next section, I’ll talk more about what you can do with pgBouncer, including some things you might not have thought possible with such a simple, lightweight tool.
Why Use SO_REUSEPORT
But what use is it? There are a lot of ways that leveraging SO_REUSEPORT can come in very useful.
-
Scaling pgBouncer
a. pgBouncer is single threaded. On a multi-threaded and/or multi-CPU machine, a single instance of pgBouncer isn’t going to do you any good, as it only works on a single thread
b. By adding more pgBouncer instances, you can use more than one thread - easy scaling! -
Provide load balancing
a. As shown in the previous section, when using SO_REUSEPORT, you effectively get load-balancing for free, at the port level of incoming traffic. We’ll discuss this further in. -
Provide rw/ro routing
a. Using different pgBouncer databases you can
i. Route read-write traffic to the database currently the primary
ii. Round-robin route read-only traffic to a number of standby databases
iii. Weight the load on a given standby by ratios you set! -
Provide failover
a. As shown in the previous section you can perform silent failover during promotion of a new primary, although you’ll need a VIP (Virtual IP address, always pointing at the primary) to do it. -
And even DoS prevention!
a. By using distinct port numbers you can provide database connections which deal with sudden bursts of incoming traffic in very different ways, which can help prevent the database from becoming swamped during high activity periods
b. This can be useful even when your applications are just sometimes “badly behaved”
So let’s run this through one at a time.
Scaling
Well, this one is quite easy. The more pgBouncer instances you have, the more resources (RAM and CPU) are available for pgBouncer to use. And because by using SO_REUSEPORT they, or at least some of them, listen on the same port - it works seamlessly for incoming connections to a shared port regardless of how many pgBouncer instances there actually are.
Load balancing
By using SO_REUSEPORT you are sharing incoming traffic at the level of the TCP stack on the shared port. This means you get a rudimentary form of load balancing for free, just by using it. This will come in handy when we are distributing traffic to various endpoints, and we’ll come back to that in the next section.
Provide rw/ro routing
Let’s say we have three databases. A primary, and two standby databases. The primary database is the only one where writes are allowed, but all three are available for reads. It would be nice to be able to pick and choose where you go to enter and retrieve data, at the application level, right? Well, we can do that.
By having a pgBouncer database called, for instance, “read-write”, we can point that connection at a VIP (Virtual IP address) which follows the primary around in case of switch- or fail-over, this is pretty easy. But what we can also do is have a “read-only” database in pgBouncer which points to the different databases you are interested in, only defined differently in each pgBouncer instance. Then you can programmatically select which connection to use in your application depending on whether you are doing OLAP (read-only) or OLTP (read-write) activity, for example, simply by using a different database when connecting to pgBouncer.
Let’s take a look at how we can set up the multiple endpoints for read-only database connections.
First, I have set up two standbys, like so:
postgres=# select application_name, client_addr, sync_state from pg_stat_replication;
application_name | client_addr | sync_state
------------------+-----------------+------------
standby1 | 192.168.152.129 | async
standby2 | 192.168.152.130 | async
(2 rows)
Now I’ll create some database definitions in my pgBouncer .ini files
bouncer1.ini
[databases]
pgbench_rw = dbname=pgbench host=127.0.0.1 user=pgbench password=foo
pgbench_ro = dbname=pgbench host=192.168.152.129 port=5432 user=pgbench password=foo
bouncer2.ini
[databases]
pgbench_rw = dbname=pgbench host=127.0.0.1 user=pgbench password=foo
pgbench_ro = dbname=pgbench host=192.168.152.130 port=5432 user=pgbench password=foo
Some points to note, here. The round-robin connectivity can not be provided by libpq, which allows multiple endpoints in a single connection string, even though pgBouncer uses libpq to connect. The connection attempt just hangs when you attempt to connect to pgBouncer if you try to set this up.
However, because we are using multiple instances of pgBouncer, listening on the same port, just pointing at different machines, the connections can now go round-robin between them. And, because we know how many of each kind of connection types we are spinning up, we also have more control over how that load is balanced. So, you can have more pgBouncer instances pointing at standby2 than at standby1, for example, if you want to divert more load to standby2.
Be careful, though: if one of your standbys goes down and you are using this kind of load balancing, you are going to unpredictably lose a proportion of your read traffic. To avoid this you can run a service that pings the databases and shuts down the appropriate pgBouncer services if they don’t respond, or add hooks to your failover manager to shut down pgBouncer as databases go down.
But, the big question, does it work?
First, I’ll send some read-write traffic to pgbench_rw (the primary, on localhost 127.0.0.1).
root@pgbouncer:~# /usr/bin/pgbench -h localhost -p 6432 -U bounce -c 4 -T 30 pgbench_rw
starting vacuum...end.
transaction type:
scaling factor: 1
query mode: simple
number of clients: 4
number of threads: 1
duration: 30 s
number of transactions actually processed: 19051
latency average = 6.300 ms
tps = 634.954188 (including connections establishing)
tps = 634.971881 (excluding connections establishing)
So that worked, which is good news, as it means that both reads and writes are being sent to the pgbench_rw (our read-write, primary) database in pgBouncer, and all the transactions completed successfully.
Just to see what happens, let’s try sending that same workload to pgbench_ro (our read-only, secondary) databases.
root@pgbouncer:~# /usr/bin/pgbench -h localhost -p 6432 -U bounce -c 4 -T 5 pgbench_ro
starting vacuum...ERROR: cannot execute VACUUM during recovery
(ignoring this error and continuing anyway)
ERROR: cannot execute VACUUM during recovery
(ignoring this error and continuing anyway)
ERROR: cannot execute TRUNCATE TABLE in a read-only transaction
(ignoring this error and continuing anyway)
end.
client 0 aborted in command 5 (SQL) of script 0; ERROR: cannot execute UPDATE in a read-only transaction
client 1 aborted in command 5 (SQL) of script 0; ERROR: cannot execute UPDATE in a read-only transaction
client 3 aborted in command 5 (SQL) of script 0; ERROR: cannot execute UPDATE in a read-only transaction
client 2 aborted in command 5 (SQL) of script 0; ERROR: cannot execute UPDATE in a read-only transaction
transaction type:
scaling factor: 1
query mode: simple
number of clients: 4
number of threads: 1
duration: 5 s
number of transactions actually processed: 0
A lot of errors complaining that the servers are in recovery, and “number of transactions actually processed: 0”. This is actually good news, as we don’t want anything other than read-only transactions going to the standbys.
Let’s see what happens with a read only workload.
root@pgbouncer:~# /usr/bin/pgbench -h localhost -p 6432 -U bounce -c 4 --transactions=10000 --select-only --no-vacuum pgbench_ro
transaction type:
scaling factor: 1
query mode: simple
number of clients: 4
number of threads: 1
number of transactions per client: 10000
number of transactions actually processed: 40000/40000
latency average = 0.761 ms
tps = 5253.376928 (including connections establishing)
tps = 5253.479261 (excluding connections establishing)
Perfect. All 10,000 transactions were completed for all 4 clients.
And, just to prove that a read-only workload is only being processed on the standbys, on both of the standby servers (shows pgbench activity coming from our pgbench session):
postgres=# select application_name, client_addr from pg_stat_activity where application_name = 'pgbench';
application_name | client_addr
------------------+-----------------
pgbench | 192.168.152.128
(1 row)
And on the primary (there is no pgbench activity):
postgres=# select application_name, client_addr from pg_stat_activity where application_name = 'pgbench';
application_name | client_addr
------------------+-------------
(0 rows)
Failover
As shown in the previous section you can perform silent failover during promotion of a new primary, although you’ll need a VIP (Virtual IP address, always pointing at the primary) to do this.
You don’t even need SO_REUSEPORT, although you can use the two in combination, just make sure all your read-write databases are pointing to the VIP and not a fixed address!
How to setup pgBouncer in hostile environments
When traffic loads become too high and you want to prioritise certain traffic over others, or when the machine pgBouncer is installed on fails, what then?
Here are some useful ideas for setting up pgBouncer in a hostile environment.
Heading off DoS attacks and badly behaved applications
As a general rule, applications connecting to your databases are well behaved. The OLTP side works well in the daytime connecting to your primary server, the batch jobs run overnight, and reporting is spread neatly across multiple standbys also during the day. All well and good.
But then, there’s that one application… Maybe it’s public facing, in the DMZ, and at risk from high traffic or denial of service attacks, or maybe it’s just badly designed. Regardless of why, you can protect the rest of the database traffic from this one relatively untrustworthy source.
By using distinct port numbers on pgBouncer you can isolate incoming traffic, and provide database connections which deal with sudden bursts of work in very different ways, which can help prevent the database from becoming swamped during high activity periods from specific applications. This can be useful for providing security on high risk applications, or even when your applications are just sometimes “badly behaved”.
So, on our test system, let’s add another pgBouncer instance to deal with high bursts of incoming traffic from a specific application, while letting the “well behaved” traffic do its job.
root@pgbouncer:~# cat /etc/pgbouncer/bouncer3.ini
;; bouncer1
;; Includes the default pgbouncer.ini file
%include /etc/pgbouncer/pgbouncer.ini
;; Overrides
[databases]
pgbench_dos = dbname=pgbench host=127.0.0.1 user=pgbench password=foo
[users]
bounce = pool_mode=transaction max_user_connections=200
[pgbouncer]
listen_addr = *
listen_port = 6433
logfile = /var/log/postgresql/bouncer3.log
pidfile = /var/run/postgresql/bouncer3.pid
auth_type = trust
unix_socket_dir = /var/run/postgresql/bouncer3_sock
so_reuseport = 0
max_db_connections = 10
Some points to note here:
- We are listening on port 6433 and using database pgbench_dos to connect. This is deliberate to keep incoming traffic isolated for this workload, even though it ultimately connects to the same database - the primary
- We have increased max_user_connections to 200, so 200 client connections can be made at any given time, but we have also dropped max_db_connections to 10, so that there will never be more than 10 database connections allowed at any given time, any more incoming traffic than can be handled by this will be buffered, or eventually simply time out, or fail altogether. There are many other settings that can be used to throttle this traffic, but this is simple and neat for a demonstration.
- I’ve turned SO_REUSEPORT off, but you can use the two in tandem.
- As before, the /var/run/postgresql/bouncer3_sock directory needs to be created by postgres
So then we just set up our unit script and start the service.
root@pgbouncer:~# cat /etc/systemd/system/bouncer3.service
[Unit]
Description=pgBouncer connection pooling for PostgreSQL: Instance 3
After=postgresql.service
[Service]
Type=forking
User=postgres
Group=postgres
ExecStart=/usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer3.ini
ExecReload=/bin/kill -SIGHUP $MAINPID
PIDFile=/var/run/postgresql/bouncer3.pid
[Install]
WantedBy=multi-user.target
root@pgbouncer:~# systemctl status bouncer3.service
● bouncer3.service - pgBouncer connection pooling for PostgreSQL: Instance 3
Loaded: loaded (/etc/systemd/system/bouncer3.service; disabled; vendor preset: enabled)
Active: active (running) since Wed 2021-03-17 12:49:55 CET; 41s ago
Process: 34068 ExecStart=/usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer3.ini (code=exited, status=0/SUCCESS)
Main PID: 34070 (pgbouncer)
Tasks: 2 (limit: 2318)
Memory: 1.2M
CGroup: /system.slice/bouncer3.service
└─34070 /usr/sbin/pgbouncer -d /etc/pgbouncer/bouncer3.ini
Mar 17 12:49:55 pgbouncer systemd[1]: Starting pgBouncer connection pooling for PostgreSQL: Instance 3...
Mar 17 12:49:55 pgbouncer systemd[1]: bouncer3.service: Can't open PID file /run/postgresql/bouncer3.pid (yet?) after start: No such file or directory
Mar 17 12:49:55 pgbouncer systemd[1]: Started pgBouncer connection pooling for PostgreSQL: Instance 3.
And we’re ready to go.
Let’s start some heavy read-write traffic on pgbench-rw.
phil@pgbouncer:~$ /usr/bin/pgbench -h localhost -p 6432 -U bounce -C -c 20 -T 600 pgbench_rw
And some heavy read-only traffic on pgbench-ro.
phil@pgbouncer:~$ /usr/bin/pgbench -h localhost -p 6432 -U bounce -C -c 20 -T 600 --select-only --no-vacuum pgbench_ro
So far so good.
What happens if we start twenty clients on port 6433, database pgbench_dos?
phil@pgbouncer:~$ /usr/bin/pgbench -h localhost -p 6433 -U bounce -C -c 20 -T 600 pgbench_dos
starting vacuum...end.
Which is working fine. htop is showing some heavy load, but that’s to be expected.
What happens when we throw a huge amount of clients at pgbench_dos, simulating sudden heavy load?
Well, we get a lot of these:
phil@pgbouncer:~$ /usr/bin/pgbench -h localhost -p 6433 -U bounce -C -c 200 -T 600 pgbench_dos
starting vacuum...end.
connection to database "pgbench_dos" failed:
ERROR: no more connections allowed (max_client_conn)
client 100 aborted while establishing connection
connection to database "pgbench_dos" failed:
ERROR: no more connections allowed (max_client_conn)
client 101 aborted while establishing connection
connection to database "pgbench_dos" failed:
ERROR: no more connections allowed (max_client_conn)
client 102 aborted while establishing connection
connection to database "pgbench_dos" failed:
ERROR: no more connections allowed (max_client_conn)
We’re actually hitting the limit on the number of database connections that can be made, even though pgBouncer accepts double what the database can spin up. The important part is that the two pgBouncer instances that are listening on port 6432 are unaffected, and carry on as usual.
So, our - admittedly basic - pgBouncer service we have spun up is protecting the other pgBouncer instances from running out of database connections.
This is great news for everyone who doesn’t want to stop doing their job, just because another application entirely isn’t doing theirs.
A useful pgBouncer architecture for resiliency
But what happens when the machine itself crashes?
Consider the usual architecture for pgBouncer:
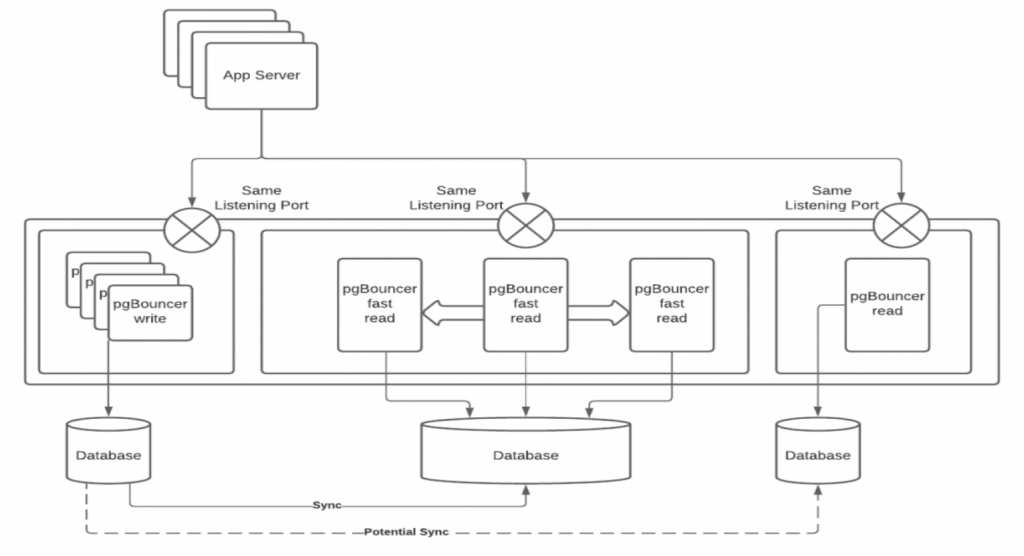
pgBouncer sits on a machine, or machines, between the application and the databases. You can add whatever you like to this architecture, and all your bets are covered. Wrong. If the machine running pgBouncer goes down, all you have added is another point of failure. If pgBouncer is unavailable, you have potentially lost all access to the database, and your application is still running, and now throwing ugly connectivity errors too.
You can add a proxy between pgBouncer and the application, checking that pgBouncer (and the databases) are still available, but then all you have done is add yet another potential point of failure to the architecture. What happens if the proxy goes down, or fails to register the availability (or not) of pgBouncer? And so it goes on.
However, there is an elegant and simple solution to this problem, named the “Laetitia Avrot” architecture, thanks to my colleague and Postgres expert Laetitia Avrot who first identified it.
Simply put, you place pgBouncer at the “highest point of failure”, or to look at it another way, you place pgBouncer at a level in the hierarchy where its failure becomes irrelevant.
In the following diagram we see pgBouncer installed on the same machine as the application itself, or perhaps the webserver (or both). If the machine the application relies on goes down, then so does pgBouncer, however if your application itself is unavailable then you have bigger problems than pgBouncer being down. You just have to make sure they are both available at the same time.
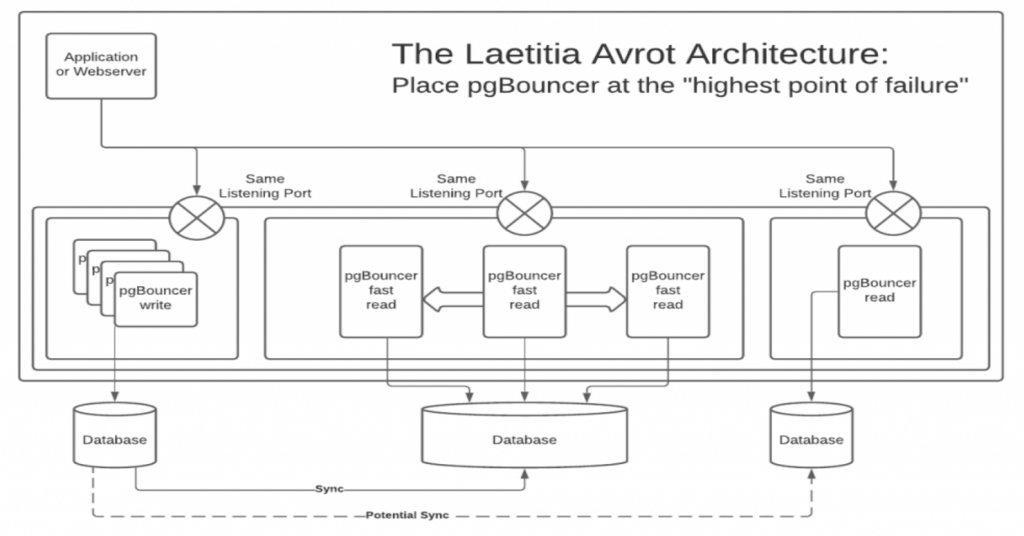
Another advantage of the Laetitia Avrot architecture is that you don’t need additional resources to run pgBouncer in the first place. Because it is lightweight and easy to manage, you can usually install it on the application server or webserver without too much impact.
And anything that can save you time, effort and money on deploying a connection pooler, that has to be worth the investment.