PG Phriday: Do’s and Don’ts of Postgres High Availability Q&A

As one of the last conferences for this year, Postgres Build 2021 has come and gone. My talk on the Do’s and Don'ts of Postgres High Availability was a kind of catch-all overview of how to avoid the worst-case scenarios we commonly encounter in the field by being proactive.
At the end of each Postgres Build session is a short 10-minute Q&A where we try to answer viewer questions. Unfortunately, I had to skip a couple of questions due to time constraints, and others deserved more comprehensive answers.
But that’s what blogs are for!
On Split-Brain
"Does EDB Postgres Distributed, and/or Postgres in general, suffer from a possible split-brain scenario if you only have 2 servers in a cluster?"
This is a two-part question and does require a bit of background in order to answer properly. Let’s start with EDB Postgres Distributed, EDB’s bi-directional logical replication (BDR) solution.
One of the mechanisms EDB Postgres Distributed uses to maintain consensus is an internal implementation of the Raft consensus algorithm. This enforces Quorum on all decisions such as adding or removing new nodes, certain DDL operations, and so on. One particular aspect of this algorithm is that operations are only permitted during a Quorum. This does not, however, affect data ingestion, as either node may accept write traffic at any time.
In this context, Split-Brain isn’t a real concern, as both nodes are meant to accept write traffic. If a write lands on both systems and happens to conflict during replay on the other system, the default behavior is to use the newest row version entirely. If this is insufficient, there are a suite of alternatives which include Conflict-free Replicated Data Types (CRDTs), column-level resolution, streaming transform triggers, and custom conflict resolution functions for specific scenarios. So long as both nodes are able to reconnect in the future, these safeguards should allow them to stitch the data back together.
But what if the nodes are separated for some interminable length of time, and the nodes are not able to re-establish communication? Maybe someone dropped a critical replication slot, or due to disk-space concerns, one of the nodes had to be forcefully removed from the cluster. Now both nodes have been separated and could reasonably contain data the other requires for a complete set.
In situations like this, EDB provides a tool called LiveCompare which can compare the content of two databases on a table-by-table basis and produce a series of batch inserts that will correct the differences. Any time a single BDR node contains writes that it can’t transmit to the remainder of the cluster, we recommend using LiveCompare to check for any data it may contain that isn’t represented on the other nodes. This applies equally to a 2-node cluster as a 50-node cluster. The isolated data is the concern, regardless of the composition of the cluster itself. If we can reintroduce that data, the temporary Split-Brain isn’t an issue.
This also applies to a more traditional Postgres cluster consisting of physical replicas. Should a node be inadvertently promoted in a way that it accepts writes when it shouldn’t, the series of corrective actions are actually very similar.
- Fence the node to prevent further unexpected writes
- Verify the applications are only reaching the intended Primary
- Use LiveCompare to compare the quarantined system with the Primary
- Verify differences should be corrected
- Apply identified changes
Afterwards, the node should be recycled back into the cluster as a replica or preserved for a few days to ensure it has no further use.
But I feel I may be answering a different question than what was asked here. The presentation itself posed the correct answer in any case. In a two-node Postgres cluster, assuming the High Availability system is also restricted to two nodes, there is no safeguard to prevent arbitrary failover. If the Standby loses contact with the Primary long enough to trigger a promotion, it will do so, and if the Primary was still online during this process, a Split-Brain is a potential outcome depending on how application traffic is routed.
This is why all comprehensive High Availability platforms provide and encourage definitions for Witness nodes. They do not have to be a full replica and provide a safeguard that prevents arbitrary failovers of this kind. This means High Availability exists outside of Postgres itself and doesn’t matter if the nodes are BDR, Postgres, EPAS, or some other variant. The HA system itself should consist of more than two nodes, rendering the architecture of the remainder of the cluster as largely moot.
And if some convoluted scenario presents itself that still results in an edge-case Split-Brain scenario, LiveCompare can correct the situation.
Out of Order
"When you stop both primary and standby and you restart them disregarding any order, could that cause a split-brain or a failover?"
A failover is a distinct possibility, but usually, the answer here is no. Most HA systems will either temporarily wait for the previous Primary node to appear, or hold an election once they determine the Primary node is missing. If the HA system on the Primary can’t interrupt the failover process, then the integrated fencing system should isolate it from the cluster, or transform it into a Standby system after the new Primary is established.
This is another reason fencing is so important. During sensitive operations such as node promotions or situations where the state of the cluster is ambiguous, the HA system must be able to isolate nodes until everything is formally operational. There may be a series of transitional states before client connections are safe, and good HA systems will effectively disable critical routing components until the cluster is ready. Patroni and EDBs HARP are two examples where the routing itself is driven by consensus, and so all traffic always goes to the expected node. Split-Brain is extremely unlikely or even theoretically impossible under these circumstances.
The “correct” answer here is, of course, not to do this in the first place. The purpose of having multiple nodes is that one or more of them is always online. If the Primary requires maintenance, perform a switchover first, then take it offline or perform whatever tasks are necessary. The likelihood of all nodes being offline at the same time is reduced for every node in the cluster. Thus while accidents can happen and two nodes may go offline, three is much less likely, and four is even safer.
Let your level of paranoia and budget availability be your guide.
Backup Plan
"Sometimes replication delay causes the replication slot to accumulate WAL segments in pg_wal. Do you recommend utilizing restore_command on the Standby as an alternative to physical replication slots?"
Yes, and also no. With the introduction of the max_slot_wal_keep_size parameter, it is now much safer to use replication slots. Should WAL files begin to accumulate, they will never exceed this amount, even if that should render the slot itself as invalid. With restore_command also provided on the Standby, it can consume WAL files from a dedicated archive until it is able to catch up and reconnect to streaming replication once more.
This gives you the best of both worlds in a real sense. Immediate availability of WAL files from the upstream Primary thanks to the slot, and if they’re still not available, it’s possible to retrieve them from another source. We often recommend this configuration when using Barman or pgBackRest, since they act both as Backup retention and WAL archives, and can provide WAL files on demand if they’re not available on the Primary for some reason.
Distributed DSNs
"Would connecting directly be ok if using Postgres multi-host connection strings?"
Given there was a slide that explicitly recommended against connecting directly to Postgres for any reason, this probably requires a bit more explanation as to why. The original question was phrased with an example host string that included two hosts and the decorator “target_session_attrs=read-write” which tells the connection library to only consider read-write nodes.
The asker probably thought this would be OK because it ensures write connections won’t reach Standby nodes, thus in a switchover event, only one node would receive traffic. There are actually two core issues here:
- This can never account for Split-Brain. If both nodes are read-write, it actually could make the problem worse, since connections could be distributed arbitrarily between both nodes.
- It seizes control of cluster management away from the HA system itself. It’s much easier to remove a VIP or CNAME, stop a proxy, reconfigure a load balancer, or otherwise isolate Postgres if there’s an abstraction layer.
This isn’t to say multi-host connection strings have no use at all! We don’t want our abstraction layer to be a single-point-of-failure either. If we’re using something like HAProxy, PgBouncer, or any other abstraction layer that requires distinct hosts, targeting several of these allows them to be offline for their own maintenance.
There’s also the distinct possibility that we add or replace database hosts over time. Proxies are much more disposable and tend to have names that are expected to outlive them. A forward-thinking network engineer might assign a similarly abstracted hostname for each database server, but that’s only one case. What if we want to add database nodes to the cluster? Do we really want to reach into configuration management to add the extra host, and then restart all of the application servers to account for the new DSN?
With a true abstraction layer insulating the database layer from the application, it doesn’t matter what architectural changes the DBAs may have in mind. So long as the interface provided to the client-side remains the same, the exact layout and state of the database layer is largely irrelevant.
The application side shouldn’t care how the database is managed.
Land of Forgotten Tools
"Any thoughts about the pg_auto_failover approach to HA?"
The pg_auto_failover HA system is a new implementation that has been gaining traction recently. Given its novelty, I haven’t performed a thorough analysis, though it appears to be a fully functional HA system which covers all of the important high points.
It follows what should be a somewhat familiar diagram, where the Monitor process fills the role of both a Witness and a kind of coordinator node:
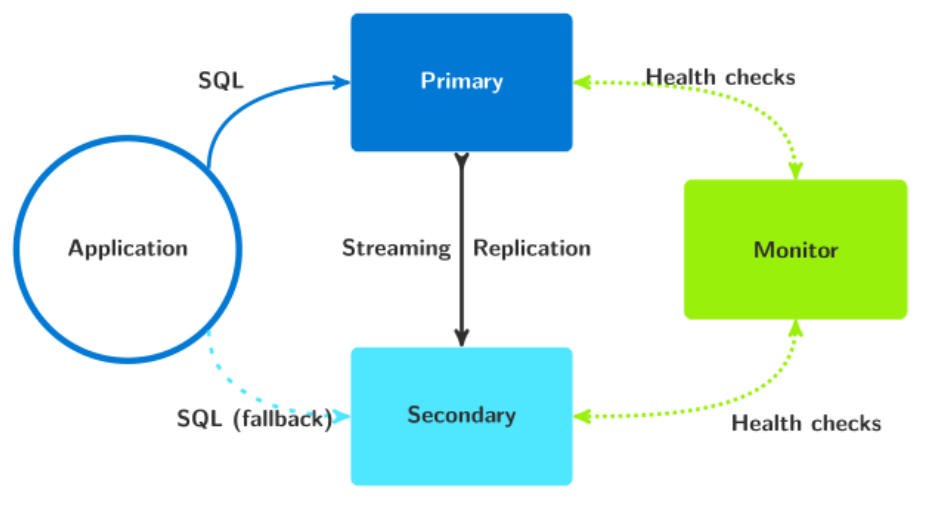
There are actually two significant drawbacks with this approach:
- It relies entirely on the Postgres multi-host string capability for connection routing. The previous discussion we had on multi-host strings applies here as well.
- The Monitor itself acts as a single-point-of-failure. Unlike most existing HA systems where every node can fill an administrative role, or otherwise relies on consensus to reach decisions, pg_auto_failover defers several operations to the Monitor process.
To somewhat address the first point, the “pg_autoctl show uri” command will provide an appropriate connection string based on the current membership and shape of the cluster. Assuming application clients or some configuration automation layer uses this regularly, it could be an appropriate substitute provided there’s adequate fencing. A short investigation seems to imply fencing is taken seriously by the Keeper process which manages each Postgres node, which is great to see.
The second point is harder to address. In other HA systems, the job of being a Monitor is an elected one. For those familiar with Stolon, each node is represented by a Sentinel process, one of which is the Leader. Thus the Leader Sentinel can change depending on the state of the cluster or the failure of a previous Leader. This isn’t the case with pg_auto_failover. Granted, this is one of the safer failure states, since it only means failover will not occur while the Monitor is offline.
All that said, it covers the principal concerns necessary for an HA system for Postgres. It requires few additional resources, needs little extra configuration, and seems easy to manage. The design itself integrates an inescapable Witness node through the Monitor, so it’s actually ahead of several other systems in that regard as well. Just keep in mind where its shortcomings reside and be prepared for those failure states.
Practicing Patroni
"We are using EFM for the future. Is Patroni a better solution?"
This is a hard question to answer. EDB’s Failover Manager, like repmgr, is one of the more traditional systems that rely on a consensus state shared between all running node management processes. This influences what decisions are made along the way. It also has integrated VIP management, and options to use hook scripts for more advanced promotion techniques or integration with other abstraction layers like PgBouncer or Pgpool-II.
On the other hand, Patroni is definitely the new kid on the block. It decouples consensus from the Postgres nodes themselves and uses a key-race system to ensure only one node can ever act as the Primary for a given cluster. What’s more, this also immediately solves the problem of connection routing, as the consensus layer always reflects the correct Primary node.
Patroni uses HAProxy to translate the state of the consensus layer to something more usable to an application layer. But since Patroni also provides an HTTP interface to obtain this information, it’s readily available to anything that can make an HTTP GET request, such as some load balancers and other proxy software. It’s extremely flexible and doesn’t rely on potentially problematic components like VIPs, CNAMEs, any issues with reconfiguring multiple PgBouncer hosts, and so on.
It’s generally a superior approach for these and other reasons. The primary complication here is that it’s quite a bit more difficult to administer. It’s necessary to initialize the consensus layer with an appropriate Patroni configuration, and modifying these parameters later is non-trivial. Postgres configuration settings may be defined in multiple locations of the initial configuration template and may lead to auto-generated configurations that defy expectations. It’s a significant hurdle, but once overcome, Patroni is nearly unrivaled in its cluster management abilities.
And all of this is exactly why I designed HARP for EDB. In the conference talk, I noted it dispenses with HAProxy in favor of a custom Proxy that directly communicates with the Consensus layer. But it also greatly simplifies definition of the cluster and management of cluster-wide settings. We’ll let everyone know once we integrate management of physical streaming replication; we can’t let Patroni have all the fun, after all.
In Conclusion
I hope you enjoyed the talk and the extended Q&A. Given the time allotted, there is a lot of information I had to skip, and hopefully, some of that was rectified here. This is one reason PG Phriday has a long list of planned topics related to High Availability; there’s just so much to say! I already have dozens of posts planned for next year, and that doesn’t count posts driven by accumulated reader questions. It’s a fascinating topic and an active development space. I’m here with EDB to ensure the discussion gets the dedication it deserves.
Please enjoy the holidays, and hopefully we’ll see you around!
Read More: PG Phriday: Isolating Postgres with repmgr