Switchover/Switchback Drill for Validating Postgres High Availability

Co-author: Vibhor Kumar
Nowadays, databases are replicated across different Data Centres and regions to mitigate any data loss and provide business continuity in case of any disaster situation arising due to natural calamities or intentional/malicious attempts. Therefore, readiness to switch over/failover to another Data Centre or different regions has become one inescapable requirement. The switchover and switchback drills need to be articulated, exercised, and performed periodically to ensure the robustness to mitigate any eventualities. EDB recommends performing switchover drills periodically to ensure such readiness.
One of the prominent EDB customers has recently planned for DC - DR drill to verify their architecture to sustain any requirements of switchover or failover in case the primary site is not available for any reason.
Readiness (Pre-drill) steps before switchover
For planned switchover, we performed the below checks before the activity at OS and database level, respectively. The mentioned steps would also be helpful for seamless failover if a situation arises.
OS level checks
- Verify resources allocated on all the servers are the same (For example, number of cores, RAM, swap, etc.)
- Verify OS version and kernel version on the systems are the same.
- Ensure database ports (5432 for PostgreSQL or 5444 for EDB Advanced Server) are open for system connections.
- Ensure ssh, without password (using SSL certificates), are allowed from all the systems.
- Verify the network connectivity across the systems and sites
Database level checks
1. Ensure the following parameters are set correctly on all the servers
listen_addresses = '*' #more details
wal_level = replica #more details
max_wal_senders = 10 #more details
max_replication_slots = 10 #more details
max_wal_size = #more details
wal_log_hints = on #more details
archive_mode = on #more details
archive_command = 'rsync -a %p /pgdata/pg_archive/%f' #need to be set as per environment #more details
2. Ensure the following parameters are set correctly across all the servers
- max_connections
- shared_buffer
- work_mem
- maintenance_work_mem,
- max_wal_size, etc.
Note: We recommend having the same value across all servers because, after switchover/failover, the load of the failed server can be appropriately managed by another server if it has the same settings and OS resources.
3.Ensure you have initial full backups of the Primary server (including postgresql.conf and pg_hba.conf)
4. Ensure to comment all cronjob entries, setup for backup, maintenance, generating reports, pgagent etc. on the primary, before performing the switchover
Switchover within the DC site using Failover Manager(EFM)
In the customer environment, we have the architecture involving two sites. The setup includes one primary, standby, and a witness instance in the DC site, and the DR site has a standby, cascading standby, and one witness instance. So each site has an EFM cluster consisting of one primary database instance, one standby database instance, and one witness node as shown below:
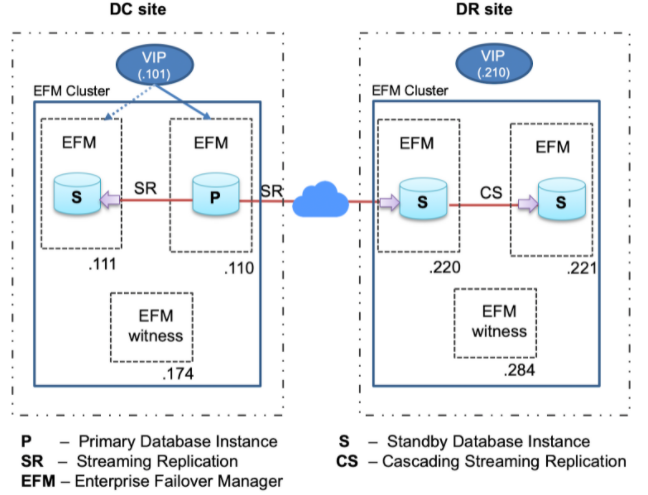
EDB Postgres Failover Manager (EFM) is a high-availability tool from EnterpriseDB that enables a Postgres Primary node to automatically failover to a Standby node in the event of a software or hardware failure on the Primary. It monitors the health of a Postgres streaming replication cluster and verifies failures quickly. When a database failure occurs, EFM automatically promotes a streaming standby node into a writable primary node to ensure continued performance and protect against data loss with minimal service interruption.
A Failover Manager cluster consists of the following.
- A primary node is a primary database server that serves database clients and applications
- One or more standby(s) nodes are streaming replication servers associated with the primary node for high availability
- The witness node confirms assertions of either the primary or standby in failover scenarios
- EDB Failover Manager (EFM) agent/daemon running on the servers (primary, standby, and witness)
In the above architecture, applications will connect to the primary database through Virtual IP(VIP). If a primary database fails, EFM will promote the standby database and transfer the VIP on the newly promoted primary instance. This way, failover will remain transparent to the applications, and there would be no requirement to make any connection string changes at the application level.
The standby database in the DR site will be connected to the primary database in the DC site using VIP. Therefore if a switchover happens within the DC site, the standby database in the DR site would keep streaming from the newly promoted standby in the DC site.
primary_conninfo = ‘host=x.x.x.101 port=5444 user=postgres’
Steps to perform the switchover
The following are the steps we used to switchover/switchback.
1. Ensure stopping applications before performing the switchover
2. Execute the following SQL to cleanup any remnant connections from the application or from unknown locations
SELECT pg_terminate_backend(<pid>)
# <pid> in the above SQL is pid of application connections which need to be terminated
3. Verify streaming replication at primary database
SELECT * FROM pg_stat_replication;
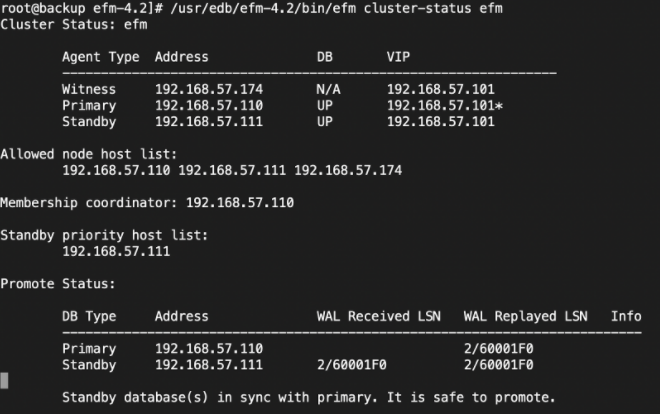
4. Verify EFM cluster status using the below command. Ensure that EFM is showing no lag at the standby database and is safe to promote
/usr/edb/efm-4.2/bin/efm cluster-status efm
5. Execute the following command to perform switchover
/usr/edb/efm-4.2/bin/efm promote efm -switchover
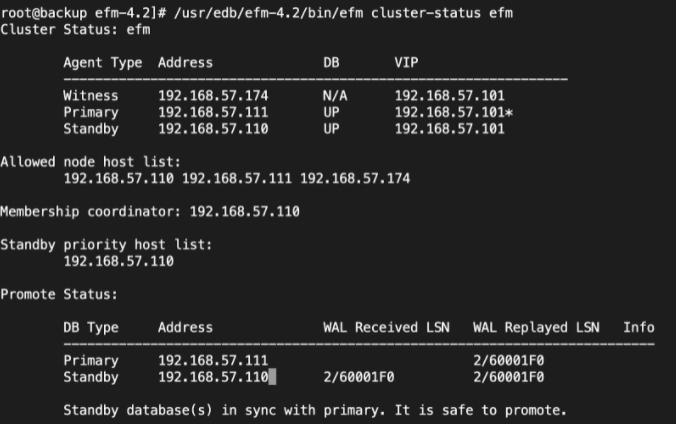
6. The above command will promote standby as the primary database, and the old primary will become a standby. Also, VIP will be automatically transferred from the old primary and to the newly promoted database. We can verify the cluster status using the below command:-
7. If you want to switch back to the old primary server (current standby), steps 1 to 6 would help you switch back
Switchover across the sites (DC to DR)
In our architecture we have two different EFM clusters across the sites. One EFM cluster is in DC and the other is in DR.
For performing the switchover across the site, we used the following steps.
DC steps for ensuring no transaction loss and standbys are synchronized
1. Ensure all applications are stopped
2. Ensure that there are no new connections coming on the database for graceful shutdown of the primary database (using pg_ctl stop option). However, for some reason if it’s not feasible to stop all the applications, we may choose any one of the mentioned below options :-
a. Change authentication method to REJECT for all application IPs in pg_hba.conf file
host all all x.x.x.112/32 reject
b. Comment all application IPs in pg_hba.conf file
#host all all x.x.x.132/32 scram-sha-256
c. Change primary database default transaction mode to read only-mode using following command
ALTER SYSTEM SET default_transaction_read_only TO on;
SELECT pg_reload_conf();
3. Terminate any application connections which are still active on the primary database
SELECT pg_terminate_backend(<pid>)
# <pid> in the above SQL is pid of application connections which need to be terminated
4. Verify the streaming replication at primary database (it should list two standby DBs, one each in DC and DR site, respectively)
SELECT * FROM pg_stat_replication;
5. Switch WAL files and perform checkpoint on primary database
SELECT pg_switch_wal();
CHECKPOINT ;
6. Verify lag between primary in DC and direct standby in DR
SELECT NOW() - pg_last_xact_replay_timestamp();
7. Perform graceful shutdown primary database in DC using following commands
sudo systemctl stop edb-efm-4.2
sudo systemctl stop edb-as-13
8. Create recovery.conf and add the following parameters in the old primary database if the PostgreSQL/EPAS version is less than 11.0 or update the following parameters in postgresql.conf if PostgreSQL/EPAS version 12 and above
standby_mode = ’on’
primary_conninfo = ’host=x.x.x.220 port=5444 user=postgres’
recovery_target_timeline = ‘latest’
restore_command = ‘rsync -a postgres@x.x.x.220:/pgdata/pg_archives/%f %p’
9. Create signal.standby file in data directory for PostgreSQL version 12 and above
touch signal.standby
10. Start the old primary database in DC as standby
sudo systemctl start edb-as-13
sudo systemctl start edb-efm-4.2
11. Now we have two standbys in DC and two in DR
DR steps for switchover
1. Verify WALs (in pg_wal) at direct standby location and ensure all are applied
2. Execute the following SQL to verify standby database is in recovery at the DR site
SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
3. Promote standby database in the DR site
sudo -u enterprisedb /usr/edb/as13/bin/pg_ctl -D /var/lib/edb/as13/data promote
4. Again verify at newly promoted database instance, output of the below SQL should show ‘f’ confirms that database is now in read-write mode
SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
5. At this stage, there will be one standby database remain configured(at DR site) from newly promoted database instance which may be verified using below command :-
SELECT * FROM pg_stat_replication;
6. Now the primary database instance in the DR site will have two standby instances i.e. one each in DR and DC site, respectively
7. Verify EFM cluster status using below command
/usr/edb/efm-4.2/bin/efm cluster-status efm
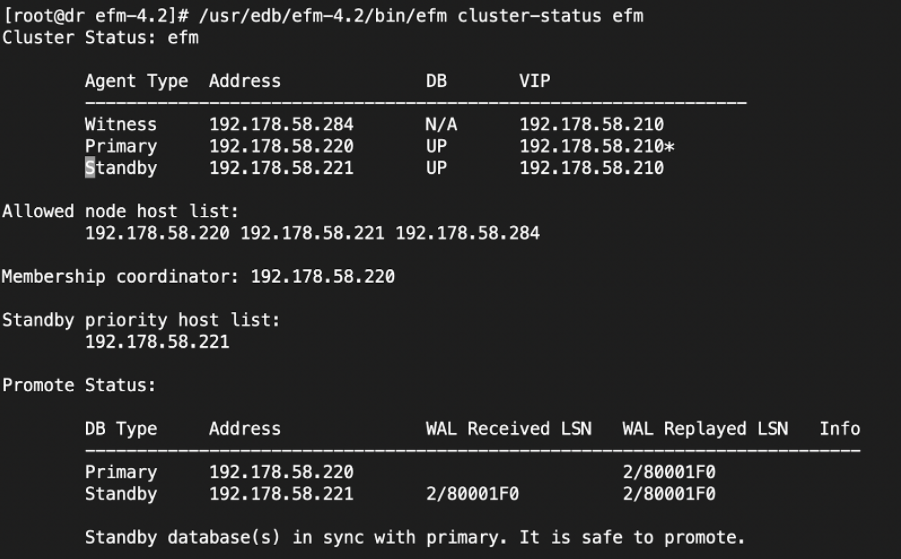
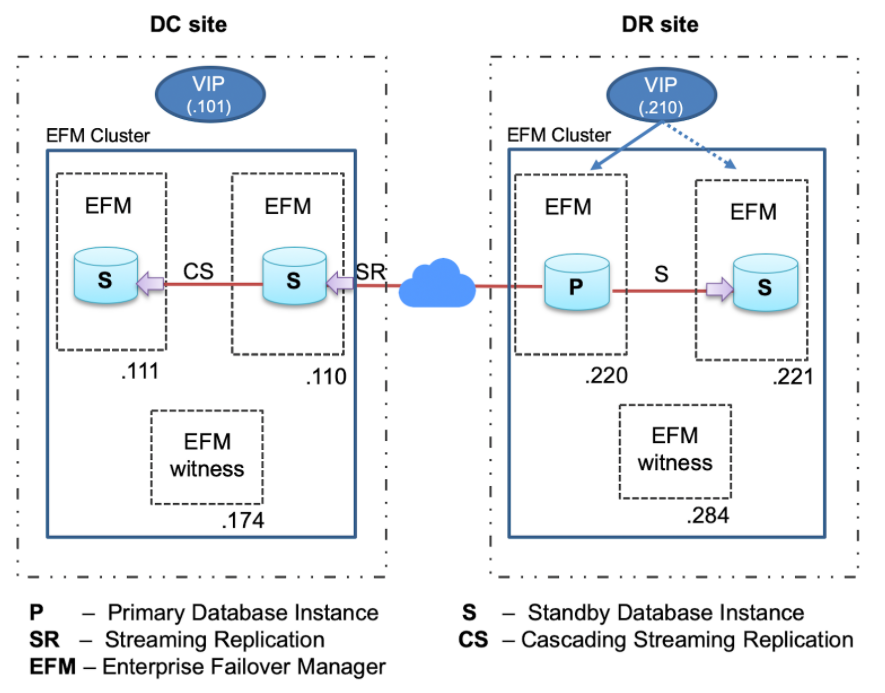
Figure 2
(after switchover from DC to DR)
8. At this stage we have finished promoting a standby to be a primary database in the DR site and the old primary in the DC site joined as a standby. The same could be verified using the below command :-
SELECT * FROM pg_stat_replication;
9. Verify connectivity from applications to primary database using EFM VIP
10. Start applications
Note: if you want to switch back to the DC site from DR, then please use the steps of “DC steps for ensuring no transaction loss and standbys are synchronized” on DR site and “DR steps for switchover” on DC site.
After performing the switchover/switchback, it is highly recommended to perform the full backup of the primary database and if you have any commented jobs or agents, please start the agents and jobs for your operation.